Buscando, por favor espere.
 Imprimir
Imprimir
 Añadir a biblioteca
Añadir a biblioteca
 Comentar este artículo
Comentar este artículo
Ortega Páez E, Ochoa Sangrador C, Molina Arias M. Estudios de supervivencia. Modelo de riesgos proporcionales. Regresión de Cox. Evid Pediatr. 2023;19:48.
En un capítulo anterior de esta serie, nos referimos al estudio de curvas de supervivencia según el método de Kaplan-Meier, válido para estimar las probabilidades acumuladas de supervivencia de una serie de sujetos en función del tiempo transcurrido de seguimiento y el evento de estudio, mediante comparaciones entre grupos diferentes definidos por un factor simple o variable categórica.
El modelo de riesgos proporcionales o regresión de Cox (RC), nombre que toma en honor al estadístico que la describió (Dave Cox, 1972), es hoy día una herramienta estadística ampliamente utilizada en medicina, esencial para el análisis de datos de supervivencia. Como cualquier modelo de regresión, es una función que analiza la relación entre una o más variables independientes o explicativas y la tasa de incidencia de un evento de interés, siendo capaz de predecir las probabilidades de supervivencia de un determinado sujeto a partir de los valores que tomen las variables predictivas. Comparte con los demás métodos de supervivencia (Kaplan-Meier) que para el cálculo del modelo computan todos los sujetos, ya que se tiene en cuenta el tiempo de todos los participantes que están en riesgo de presentar el evento en cada instante, tanto si el tiempo de seguimiento es completo hasta presentar el evento de interés o incompleto (censurados). A diferencia de otros modelos de regresión (lineal, logística) es un modelo dinámico, no solo nos dice el número de eventos que ocurren, sino a la velocidad a la que ocurren.
La RC es especialmente útil en:
El modelo es el producto de dos funciones. La primera dependiente del tiempo [h0(t)], y la segunda dependiente de las variables predictoras X (eβx). Se considera un modelo semiparamétrico, ya que la primera función, que se obtiene a partir de los datos, está libre de cualquier distribución, mientras que la segunda función depende de la distribución de las variables predictoras.
La ecuación de regresión de Cox se puede expresar como:
$$ h(t;X) = h_0(t)*e^{β'x}=h_0(t)*e^{{β_1x_1}+{β_2x_2}+{β_i\space x_i}} $$
Tomando logaritmos neperianos se puede expresar como modelo log-lineal.
$$Inh(t;X) = Inh_0(t)+{β_i\space x_i}$$
h(t;X). Función de riesgo. Representa la tasa de riesgo de un sujeto con valores = X (X1, X2… Xn) de la/s variable/s explicativas en un instante de tiempo determinado (t). Es la variable dependiente, codificada como 0: si, 1: no.
h0(t). Tasa basal de riesgo, que solo depende del tiempo. Representa la tasa instantánea de riesgo cuando el valor de las variables predictoras es igual a 0. Esta variable está unida en el análisis a la variable dependiente.
eβ'x. Función exponencial. Es la combinación lineal de las variables predictoras o explicativas (Xn), que pueden ser cualitativas o cuantitativas.
Matemáticamente, hazard (λt) en un tiempo t determinado se podría expresar como: número de eventos ocurridos (di) en un preciso instante dividido por el número total de personas en riesgo (ni). Como es lógico, este riesgo instantáneo va cambiando durante el tiempo, dando lugar a una función de riesgo.
$$λ_t= {d_i\over n_i} $$
H(t;X) = H0t ∗ eβ'x; tomando logaritmos neperianos, tenemos H(t;X) = -ln S(t;X)
$$S(t;X)=e^{-H(t;x)} $$
La estimación de los parámetros se realiza mediante la función de verosimilitud “parcial”, porque la fórmula de probabilidad solo considera probabilidades para aquellos sujetos que mueren/fallan y no considera las probabilidades para aquellos sujetos que son censurados; dicho de otra manera, considera las verosimilitudes solo de los cambios ocurridos y no todos los sujetos de la muestra. Sin embargo, en el cálculo de las probabilidades de los tiempos de muerte sí tiene en cuenta todos los sujetos objeto de riesgo al inicio de los diferentes tiempos de muerte.
Veamos el caso más sencillo, donde la variable explicativa es cualitativa binaria X (0/1). Por ejemplo, un estudio que valore la muerte en grandes prematuros en función de presentar encefalopatía grave (X = 1) o no (X = 0).
$$h(t;X)= h_0(t)*e^{βx} $$
El hazard para cada grupo en el tiempo t sería:
$$h(t;X=1)= h_0(t)*e^β;h(t;X=0)=h_0(t)*e^0. $$
El HR sería:
$$HR= {h(t;X=1)\over h(t;X=0)} = {h_0(t)*e^β\over h_0(t)*e^0}=e^β → h(t;X=1)=e^β*h(t;X=0)$$
Esto quiere decir que la HR es equivalente a eβ y, como puede verse, es independiente del tiempo, solo depende de los datos de la variable explicativa. Se podría concluir que es el factor por el que se multiplica la tasa instantánea de riesgo cuando el valor de X aumenta en una unidad. En el ejemplo que nos ocupa con variable cualitativa, el valor se interpretaría como el cociente de riesgo instantáneo de muerte entre los grandes prematuros con encefalopatía grave respecto a los que no la tienen. En el caso de una variable cuantitativa (continua o discreta), el valor sería multiplicado por cada unidad de cambio de la variable X. Si β es positivo (+) nos indica un aumento de la tasa instantánea de riesgo cuando aumenta el valor de X (HR >1), y cuando tiene un signo negativo (-) significa una disminución de la tasa instantánea de riesgo al aumentar el valor de X (HR <1).
La significación estadística de la tasa de riesgo de la ocurrencia del evento y las variables explicativas se comprueban por la prueba de significación del coeficiente β y por el intervalo de confianza del coeficiente exponenciado (eβ) .
La prueba de significación se estudia mediante la prueba de Wald (z), que compara el coeficiente β dividido por su error estándar (EE) con la ley normal estandarizada bajo la hipótesis nula de que z = 0.
$$Z= {β\over EE}; → (0,1); $$
Valores de p <0,05 suponen que el coeficiente es significativo. Hay que decir que esta prueba es válida para muestras grandes. Cuando las muestras son pequeñas o la significación está cercana a 0,05 se recomienda realizar la prueba de verosimilitud que converge más rápido hacia la distribución normal.
El intervalo de confianza al 95% (IC 95) de eβ se calcula de la siguiente forma:
IC(95)= eb ∗ e±1,96EE. Donde el límite inferior (LI) = eb ∗ e-1,96EE; límite superior (LS)= eb ∗ e+1,96EE. Si el IC 95 contiene el valor nulo (la unidad) entonces el coeficiente no es significativo.
Veamos un ejemplo utilizando un programa de acceso libre, el software estadístico R (https://www.r-project.org/) con el plugin RCommander (https://www.rcommander.com/) y la base de datos EeP_Fund_SupervivenciaT12m.RData (https://evidenciasenpediatria.es/files/43-227-RUTA/EeP_Fund_SupervivenciaT12m.RData). Si necesita saber cómo instalar RCommander, puede consultar el siguiente tutorial en línea: http://sct.uab.cat/estadistica/sites/sct.uab.cat.estadistica/files/instalacion_r_commander_0.pdf
En la base de datos se recogen una serie de registros sobre la duración de la lactancia materna en un grupo de madres con sus hijos, además de otras variables, como el peso del recién nacido, la edad, el tipo de parto, el nivel de educación, etc. Tres variables tienen especial relevancia para el ejemplo:
La instalación básica de RCommander no incluye las rutinas para realizar las técnicas de análisis de supervivencia, por lo que, antes empezar, debemos cargar un plugin (una extensión) denominado RcmdrPlugin.survival.
Una vez que hemos abierto el programa R, debemos instalar el paquete correspondiente al plugin (si no se ha instalado y usado antes), para lo cual, el método más rápido es teclear el comando install.packages(RcmdrPlugin.survival). Si este método falla, puede seleccionarse en R el menú Paquetes → Instalar paquetes(s)… y seleccionar un CRAN de la lista que ofrece la ventana emergente. Una vez hecho, veremos la lista de todos los paquetes de R ordenados alfabéticamente. Buscamos y marcamos RcmdrPlugin.survival y pulsamos OK.
Nuestra intención es estudiar si la duración de la lactancia materna está relacionada con la edad de madre mayor o menor de 30 años.
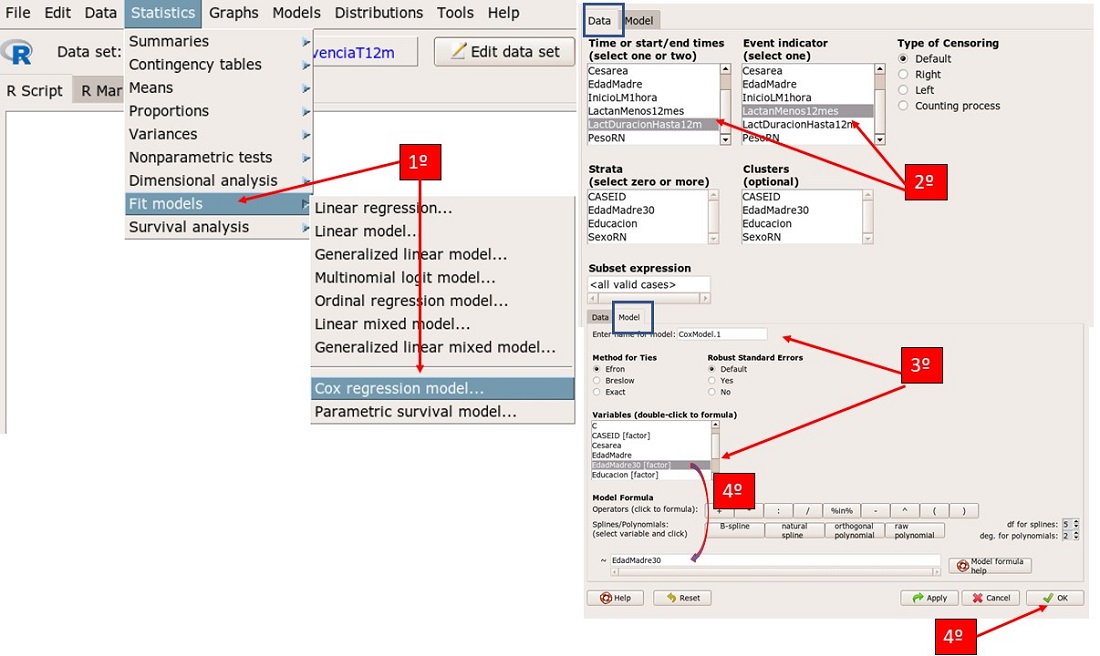
Para construir el modelo de Cox nos vamos a la pestaña de Rcommader de Statistics (estadística) → Fif models (ajuste de modelos) → Cox regression model (modelos de regresión de Cox). Se nos despliega un cuadro de dialogo donde debemos introducir las variables. En la pestaña Data (datos) en la ventana Time or start/and times (tiempos de inicio y final) introducimos la variable tiempo transcurrido (LactDuracionHasta12m) y en la ventana Event indicator (indicador del evento) la variable LactanMenos12mes, el resto de las ventanas las dejamos libres, ya que no vamos a aplicar ninguna estratificación, a continuación, seleccionamos todos los casos (Subset expression: all vallid cases). En la pestaña Model (modelo) seleccionamos el método de realización del modelo Method for ties (método) Efron que viene por defecto, los errores estándar robustos (Robust Standard Errors → Default) y le damos nombre al modelo (CoxModel.1). En la ventana Variables clicamos la variable explicativa Edad30 que está codificada como factor y se nos coloca en el cajón inferior (Model Formula- Fórmula del modelo). El resto lo dejamos como está y clicamos en OK (figura 1).
Figura 1. Construcción de un modelo de Regresión Cox en R. Mostrar/ocultar
En la figura 2 ofrecemos la ventana de salida con los resultados.
Figura 2. Resultados Regresión de Cox en R. Mostrar/ocultar
En primer lugar, nos aparece el nombre del modelo (CoxModel.1), la función en R coxph(Surv), las variables (LactDuracionHasta12m, LactanMenos12mes) ~ EdadMadre30, el método con el que se ha realizado el modelo (method=“efron” y, por último, el nombre de la base de datos (data=EeP_Fund_SupervivenciaT12m). Se ha elegido el método de efron porque es el más válido en caso de empates y se acerva mucho al método exacto. Obsérvese que en la fórmula del modelo de regresión la variable dependiente está “unida” en el análisis a la variable tiempo trascurrido (primera parte de la ecuación).
Seguidamente, debemos fijarnos en el número total de registros (2195) y el número de eventos (las madres que han dejado la lactancia antes del año, 1821). En el modelo hay que destacar que la comparación se establece en la categoría de <30 años, el coeficiente β (coef: -0,2099), el coeficiente exponenciado (exp(coef)eβ:0,81065, que corresponde con la HR, el error estándar del coeficiente (se (coef); 0,05), la prueba z de Wald para la significación el mismo (z: -3,53) y la probabilidad de la prueba (Pr)>z: 0,000403, que nos indica que es significativa p <0,0001(***), y los límites inferior y superior del IC 95 de la HR: 0,72 a 0,91.
Podríamos concluir que las madres lactantes de <30 años tienen un 18,94% (HR: 0,8106) menor riesgo de perder la lactancia al año respecto a las ≥30 años. El IC 95 no incluye el valor nulo (1), lo que significa que la relación es significativa estadísticamente. R nos ofrece el valor del coeficiente exponenciado negativo (exp(-coef: 1,23), que en el caso de variables explicativas protectoras facilita la interpretación, al invertir la categoría de referencia, lo que se interpretaría como que las mujeres de ≥30 años tienen un 23% más riesgo de perder la lactancia materna que las de <30 años. R no nos ofrece el IC 95 (1,095 a 1,38), hay que calcularlo manualmente con la fórmula vista anteriormente:
$$ Límite\space inferior\space (LI)=e^b *e^{-1,96EE}=e^b*e^{-1,96*0,0593}=1,095$$
$$ Límite\space superior\space (LS)=e^b *e^{+1,96EE}=e^b*e^{+1,96*0,0593}=1,38$$
Para la aplicación de una RC es necesario que se cumplan ciertos supuestos:
La violación de este supuesto se puede corregir de dos formas. Estratificando por la variable que no cumple este supuesto o introduciendo una variable que represente el tiempo de seguimiento de cada variable que no sigue el supuesto y que se comporta como un término de interacción que multiplica su valor por el de la variable explicativa en cuestión. A este modelo extendido de la regresión de Cox se le denomina regresión de Cox dependiente de tiempo.
$$ln(t;X)=Inh_0(t)+ b_ix_i.$$
Se realiza por tres pruebas de hipótesis: prueba de razón de máxima verosimilitud (Likelihood ratio test), prueba de Wald y el Score (longrank) test. Son pruebas de hipótesis globales, tienen en cuenta todas las variables del modelo y siguen una distribución Χ2gl=n; donde n = n.º de variables del modelo.
Es frecuente en los modelos de regresión medir el grado de varianza explicada por el modelo ajustado por el valor de la R2. En la RC la R2 no es un buen parámetro, ya que su valor nunca puede llegar a 1 por el término no paramétrico del modelo. Por esta razón los paquetes informáticos proporcionan la Concordance (concordancia), que se interpretaría como la clasificación correcta de los pares de observaciones en términos de tiempo hasta el evento. Es útil para evaluar la capacidad predictiva del modelo, se considera como una generalización del área bajo la curva ROC en modelos de supervivencia. La concordancia toma valores entre 0 y 1, donde un valor de 0,5 indica que el modelo no tiene capacidad de discriminación (similar a una moneda lanzada al aire) y un valor de 1 indica una capacidad perfecta de discriminación (todos los individuos se clasifican correctamente según su riesgo).
Se puede estudiar de dos formas, mediante gráficos o por pruebas de hipótesis.
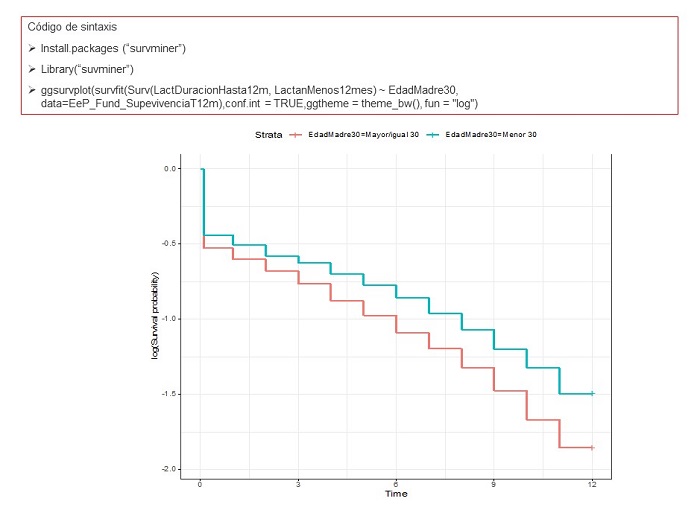
El más sencillo es la comprobación de las curvas de supervivencia ajustadas por el modelo para cada categoría de la variable explicativa, donde se relaciona el logaritmo de la probabilidad de supervivencia en el eje de la Y con el tiempo trascurrido en el eje de la X. Si las curvas de supervivencia son paralelas entre sí, podemos asumir que los cocientes de riesgos instantáneos a lo largo del tiempo son proporcionales.
Gráfico de los residuos de Schoenfield escalados. Se calculan por cada variable del modelo por separado. Son la diferencia de los valores obtenidos por el modelo de cada variable ajustados por las demás covariables y los valores esperados en un momento dado, calculado por el promedio ponderado (multiplicando cada valor por el inverso de la varianza) de los valores de las covariables entre todos los individuos que están en riesgo en ese momento dado. La gráfica muestra los valores de los residuales en el eje de la Y ordenados frente al tiempo de estudio en el eje de la X. El supuesto de proporcionalidad se cumple si los valores son independientes del tiempo (no existe ningún patrón de distribución), se distribuyen alrededor del valor 0 y comprendidos entre +/- 2 desviaciones estándar.
Es más confiable que el anterior, ya que a veces la inspección gráfica puede ser engañosa. Se realiza mediante una correlación lineal entre los residuos escalados de Schoenfield y el tiempo de estudio. Bajo la hipótesis nula de que la ausencia de correlación (H0 = ρ = 0) es sinónimo de riesgos proporcionales. Valores p <0,05 suponen rechazar la hipótesis nula de riesgos proporcionales.
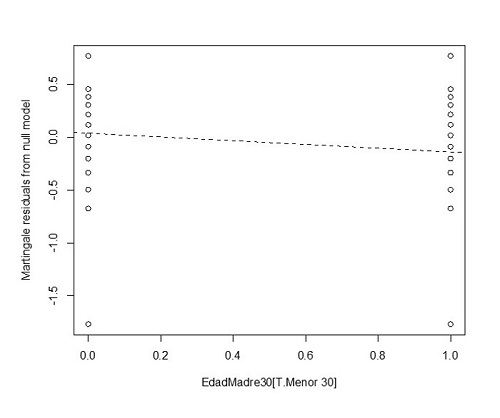
Este supuesto solo es aplicable a las variables continuas. Se realiza mediante los residuos de Martingala, que son los valores calculados por el modelo menos los esperados. Tienen una distribución asimétrica. El gráfico se obtiene representando los residuos de Martingala del modelo nulo en el eje de la Y frente a los residuos estimados por el modelo. Valores alrededor del 0 suponen que no existe linealidad, valores cercanos a 1 suponen que los individuos tuvieron el evento demasiado pronto y valores cercanos a 0 suponen que lo tuvieron demasiado tarde.
Siguiendo con nuestro ejemplo, tenemos:
En la última fila de la figura 2 representamos el criterio de bondad de ajuste del modelo. Vemos cómo la prueba de verosimilitud parcial (p = 0,0003), la prueba de Wald (p = 0,0004) y la prueba Score (p = 0,0004) son todas significativas, hecho que apoya que el modelo reproduce la probabilidad pronosticada. Es de destacar que la prueba de verosimilitud parcial es la más potente.
Por último, la concordancia del modelo es de 0,52. Lo que significa que el modelo es poco discriminativo.
La comprobación de los tres supuestos que vienen a continuación se realiza con el estudio de los residuos, que no son más que los valores observados menos los esperados por el modelo más o menos transformados.
Figura 3. Comprobación supuesto de riesgos proporcionales. Curvas de logaritmo de la supervivencia ajustada y tiempo. Mostrar/ocultar
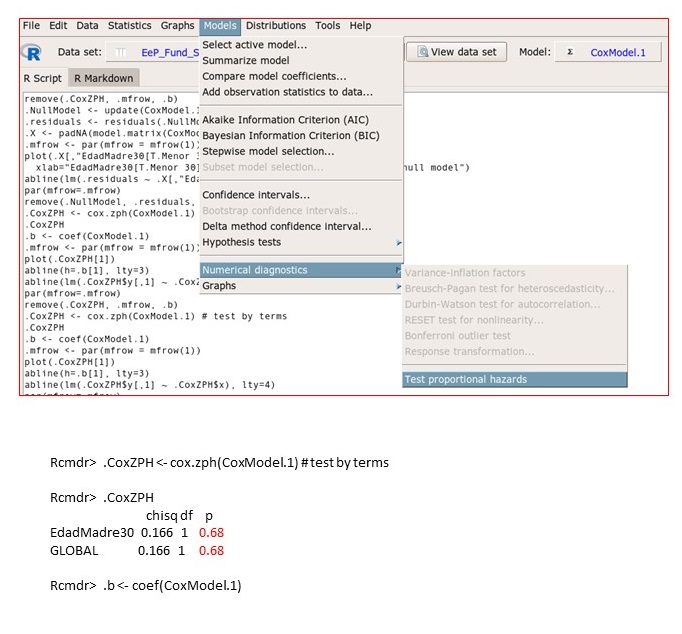
Rcommander realiza el gráfico de los residuales de Schoenfield y la prueba de hipótesis mediante la función cox.zph() en la pestaña Models (modelos) → Numerical diagnostics (diagnósticos numéricos). Computa bien la prueba de hipótesis (figura 4), pero da error en la gráfica de los residuos de Schoenfield, al no calcular bien los grados de libertad de la prueba (df), ya que por defecto utiliza df = 4.
Figura 4. Comprobación supuesto riesgos proporcionales. Prueba de hipótesis. Mostrar/ocultar
La prueba realiza dos contrastes: uno global, que incluye todas las variables del modelo, y otro por cada variable por separado, en este caso al existir una única variable ambos contrastes coinciden. Observamos que la prueba no es significativa (p = 0,68), lo que implica que no es posible rechazar la hipótesis nula de riesgos proporcionales.
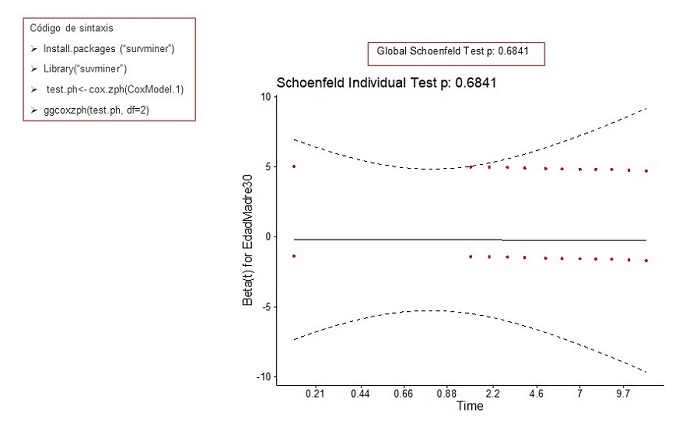
Para realizar el gráfico de Schoenfield es necesario hacerlo de forma manual limitando el análisis a df = 2 (figura 5). Podemos observar que los puntos de ambas categorías están dispersos en una línea horizontal, indicando que el supuesto de proporcionalidad se cumple. También nos ofrece la prueba de hipótesis vista anteriormente (p = 0,68).
Figura 5. Comprobación supuesto riesgos proporcionales. Método gráfico y prueba de hipótesis. Mostrar/ocultar
Figura 6. Supuesto de no linealidad. Residuos de Martingala. Mostrar/ocultar
Figura 7. Residuales DFBETA y DFBETAS. Mostrar/ocultar
El riesgo relativo (RR) y la odds ratio (OR) nos dan una fotografía en un momento dado, son medidas estáticas de riesgo. La HR es dinámica, ya que tiene en cuenta el tiempo en que se producen los sucesos, y nos ofrece una película a través del tiempo. Los tres estimadores ofrecen resultados diferentes. El RR siempre estará más cercano a la unidad, la OR será la más lejana y la HR estará en una posición intermedia. Cuanto más largo sea el seguimiento, mayor la incidencia de eventos y mayor el valor del RR, más divergencia habrá entre RR y HR. El motivo es que la RC tiene en cuenta el momento concreto en que se produjo el evento y los datos censurados, de ahí que los denominadores a lo largo del tiempo vayan cambiando, siendo cada vez menores; esto trae consigo un aumento de la HR. Debemos tener en cuenta que la equivalencia de los tres parámetros pierde sentido si los seguimientos de los pacientes no son homogéneos.
Ortega Páez E, Ochoa Sangrador C, Molina Arias M. Estudios de supervivencia. Modelo de riesgos proporcionales. Regresión de Cox. Evid Pediatr. 2023;19:48.


 Artículo completo
Artículo completo
 PDF
PDF