Buscando, por favor espere.
 Imprimir
Imprimir
 Añadir a biblioteca
Añadir a biblioteca
 Comentar este artículo
Comentar este artículo
Ochoa Sangrador C, Molina Arias M. Evaluación de la precisión de las pruebas diagnósticas (2). Variables continuas. Evid Pediatr. 2017;13:45.
En documentos previos de esta serie hemos abordado cómo evaluar la validez de una prueba diagnóstica. También hemos revisado cómo medir su precisión o fiabilidad. Hasta ahora hemos mostrado los métodos de medición de la precisión para datos discretos nominales (índice kappa) y ordinales (índice kappa ponderado). Ahora abordaremos los métodos correspondientes a datos continuos: la desviación estándar intrasujetos, el coeficiente de correlación intraclase y el método de Bland y Altman.
Cuando el resultado de una prueba se mide en una escala continua, podemos estimar el error de medición calculando la variabilidad existente entre medidas repetidas en los mismos sujetos. El parámetro que mejor refleja dicha variabilidad es la desviación estándar intrasujetos (excluyendo la observada entre sujetos). Para calcularlo necesitamos una serie de sujetos a los que se les realicen al menos dos mediciones. En la tabla 1 se presentan los resultados de dos mediciones repetidas de bilirrubina transcutánea en recién nacidos ictéricos1. La desviación estándar intrasujetos puede calcularse fácilmente usando un programa que realice análisis de la varianza (ANOVA). El ANOVA descompone la variación que hay entre el conjunto de mediciones (estimada a través de la diferencia de cada valor respecto la media global al cuadrado) en varios componentes: la variación entre las mediciones de los diferentes sujetos (entre las filas de la tabla 1) y la variación residual, que en una ANOVA de un factor corresponde a la variación entre las mediciones de cada sujeto (entre las columnas de la tabla 1).
Tabla 1. Resultados de dos mediciones repetidas de bilirrubina transcutánea (Jaundice-Meter 101, Minolta Air Shields), en la cara anterior del tórax en 20 recién nacidos ictéricos. Datos extraídos de un estudio más amplio3. Mostrar/ocultar
En la tabla 2 podemos ver el ANOVA para los datos de la tabla 1. El parámetro denominado cuadrados medios de los residuos (CMr) es la varianza residual o intrasujetos (que depende de las diferencias entre las mediciones repetidas de cada sujeto). Si realizamos la raíz cuadrada de CMr obtendremos la desviación estándar intrasujetos (si). La si puede calcularse igualmente a partir del ANOVA para estudios con más de dos mediciones por sujeto.
Tabla 2. Análisis de la varianza de una vía de los datos de la tabla 1. Mostrar/ocultar
Utilizando la si podemos cuantificar el margen de error de nuestras mediciones. Así, podemos estimar que la diferencia entre una medición determinada y el verdadero valor no será mayor de 1,96 veces la si en el 95% de las observaciones (asumiendo que siguen una distribución normal, el 95% de las determinaciones caerán en el intervalo entre el valor verdadero más menos 1,96 veces la desviación estándar). También nos permite estimar que la diferencia entre dos mediciones repetidas en un mismo sujeto no superará 2,77 veces la si en el 95% de las observaciones2,3. Para nuestro ejemplo, la si es 0,54 (raíz cuadrada de 0,3), por lo que la diferencia estimada respecto al valor verdadero será menor de 1,05 (1,96 × 0,54) y la diferencia entre dos mediciones será menor de 1,49 (2,77 × 0,54).
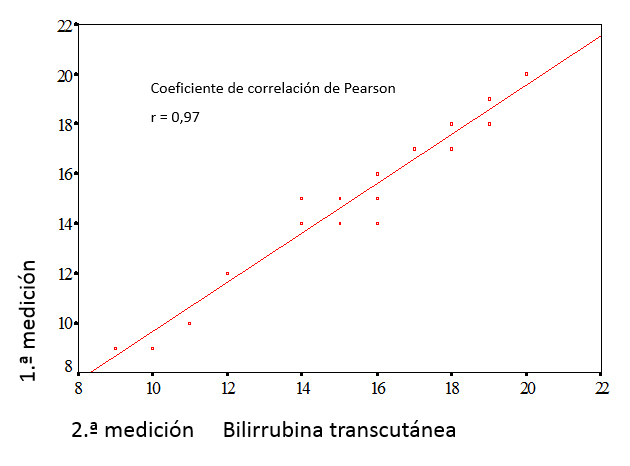
Si solo se realizan dos mediciones por sujeto, la forma más intuitiva de compararlas es representar las parejas de mediciones en un diagrama de puntos, examinando si existe relación lineal entre ambas y calcular su coeficiente de correlación. En la figura 1 se presenta el diagrama de puntos de los datos de la tabla 1. El coeficiente de correlación de Pearson (r) para estos datos es 0,97 (cuanto más se aproxima a 1, mejor es la correlación).
Figura 1. Diagrama de puntos y correlación lineal de los datos de la tabla 1. Mostrar/ocultar
Sin embargo, la existencia de una fuerte relación lineal con un alto coeficiente de correlación no indica que haya una buena concordancia entre las mediciones, solamente que los puntos del diagrama se ajustan a una recta. El coeficiente de correlación depende en gran manera de la variabilidad entre sujetos, por ello, varía mucho en función de las características de la muestra donde se estima, afectándole especialmente la presencia de valores extremos. Si una de las mediciones es sistemáticamente mayor que otra, el coeficiente de correlación será muy alto, a pesar de que las mediciones nunca concuerden. Estos problemas son evitados utilizando el coeficiente de correlación intraclase.
El coeficiente de correlación intraclase (CCI) estima la concordancia entre dos o más medidas repetidas. El cálculo del CCI se basa en un modelo de ANOVA con medidas repetidas, aplicándose distintas fórmulas en función del diseño y los objetivos del estudio4. El escenario más simple es aquel en el que estimamos la variabilidad de las medidas, sin tener en cuenta la variabilidad aportada por los distintos observadores (diseño de una vía con factor aleatorio). Considerando este diseño, y utilizando los resultados del ANOVA, podemos calcular el CCI con la siguiente fórmula:
$$CCI=\frac{CMp-CMr}{CMp+(k-1)CMr},$$donde k es el número de observaciones por sujeto, CMp son los cuadrados medios entre pacientes (que depende de las diferencias de las mediciones entre sujetos) y CMr los cuadrados medios de los residuos (que depende de las diferencias entre las mediciones repetidas de cada sujeto).
Con los datos del ANOVA de la tabla 2 el CCI será:
$$CCI=\frac{19,55-0,30}{19,55+(2-1)0,30}= 0,96.$$En nuestro ejemplo, apenas hay diferencias entre el CCI y el coeficiente de correlación de Pearson (r). Si el CCI fuera mucho menor que r, habría que pensar que existe un cambio sistemático entre una medida y otra, lo que podría estar causado por un efecto de aprendizaje. En este caso, las mediciones no se habrían realizado en las mismas circunstancias, por lo que no se darían las condiciones para realizar un estudio de fiabilidad5.
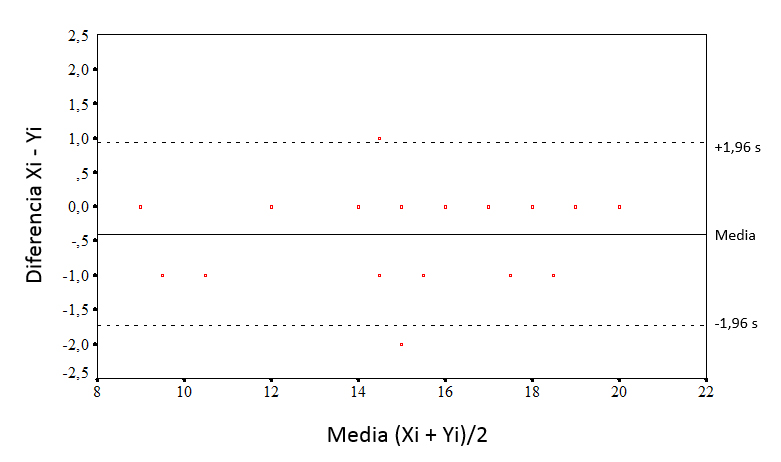
Un método alternativo para analizar la concordancia entre dos observaciones repetidas que se miden en una escala continua es el método gráfico descrito por Bland y Altman6. Consiste en representar en un diagrama de puntos la diferencia entre los pares de mediciones contra su media (figura 2). Los puntos tienden a agruparse alrededor del cero para las diferencias entre las dos mediciones, de forma que cuanto mayor sea el grado de dispersión alrededor del cero, peor será el acuerdo entre los dos métodos. Una forma de valorarlo sería dibujar las líneas horizontales en el nivel de diferencia máxima que puede ser tolerable desde el punto de vista clínico y ver si los puntos, o la mayoría de ellos, se agrupan entre estas dos líneas horizontales. De forma alternativa, se puede estimar la desviación estándar de las diferencias y los intervalos entre los que cabe esperar que se encuentre el 95% de ellas.
Figura 2. Método de Bland y Altman con los datos de la tabla 1. Mostrar/ocultar
Este método también permite examinar la magnitud de las diferencias y su relación con la magnitud de la medición. Cuando la variabilidad en las medidas no es constante, sino que cambia al aumentar o disminuir la magnitud de la medida, el cálculo se complica7. Si existe correlación significativa entre las diferencias y las medias, la variabilidad no será constante (puede haber un acuerdo aceptable en determinado intervalo de valores, pero no en otros). En ese caso, puede intentarse realizar transformaciones logarítmicas de los datos o analizar la variabilidad por separado para varios intervalos de valores, aunque siempre tendremos que cuestionarnos la validez de la medición en ese intervalo.
Ochoa Sangrador C, Molina Arias M. Evaluación de la precisión de las pruebas diagnósticas (2). Variables continuas. Evid Pediatr. 2017;13:45.


 Artículo completo
Artículo completo
 PDF
PDF