Buscando, por favor espere.
 Imprimir
Imprimir
 Añadir a biblioteca
Añadir a biblioteca
 Comentar este artículo
Comentar este artículo
Molina Arias M, Ochoa Sangrador C. Estudios observacionales (II). Estudios de cohortes. Evid Pediatr. 2014;10:14.
Los estudios observacionales son aquellos en los que los investigadores actúan como meros observadores, sin ejercer ningún tipo de influencia sobre los factores de exposición. De este tipo de estudios, los que proporcionan una mejor calidad de evidencia científica son los estudios de cohortes, de los que hablaremos a continuación, y los estudios de casos y controles.
Una cohorte designa un grupo de sujetos que tienen una característica en común, que generalmente es la exposición al factor de estudio. Esta característica común puede ser de naturaleza diversa, como una característica genética, un factor social o geográfico, un grupo profesional específico, etc.
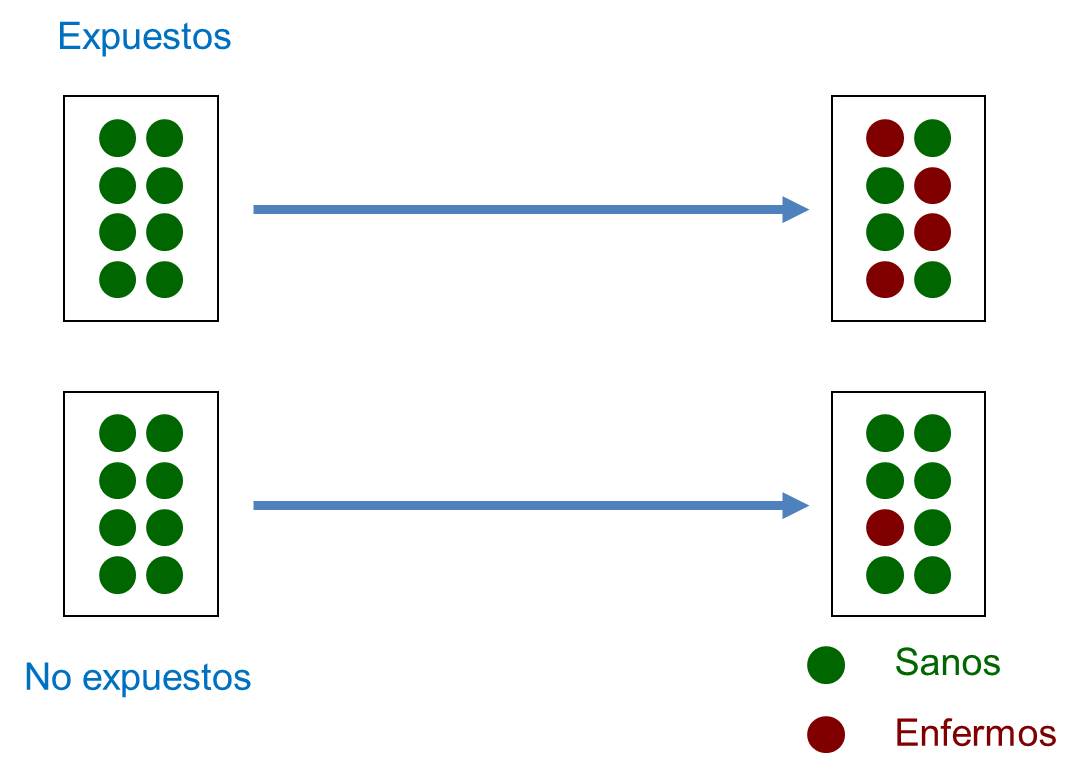
La característica que define un estudio de cohortes es que los sujetos son escogidos por estar expuestos o no a ese factor de interés. Un estudio de cohortes es un diseño de tipo observacional, analítico (hay grupo de comparación) y longitudinal, habitualmente anterógrado (de la exposición al efecto) y de temporalidad concurrente o mixta (el investigador asiste al efecto). En estos estudios, una cohorte o grupo de individuos expuestos a un factor de estudio es observada a lo largo del tiempo para comprobar qué le ocurre en comparación con otra cohorte de sujetos no expuestos (figura 1). Los participantes son seguidos hasta que desarrollan el efecto, hasta que se pierden durante el seguimiento o hasta la finalización del estudio.
Figura 1. Esquema del diseño de un estudio de cohortes. Mostrar/ocultar
En función de la relación cronológica entre el inicio del estudio y la producción del efecto de interés, los estudios de cohortes pueden clasificarse en prospectivos y retrospectivos.
El diseño prospectivo es el más típico de este tipo de estudios. Las dos cohortes, expuesta y no expuesta, se forman antes del desarrollo del resultado o enfermedad de interés, y se siguen a lo largo del tiempo para comparar la ocurrencia del resultado de interés entre ambos grupos. En otras ocasiones, tanto la exposición como el efecto ya han ocurrido cuando se inicia el estudio (cohortes retrospectivas o históricas), identificándose ambas cohortes en una fecha previa determinada que esté lo suficientemente alejada como para que haya habido tiempo suficiente entre exposición y producción del efecto. En menos ocasiones, los estudios de cohortes son ambispectivos, es decir, se recogen datos prospectivos y retrospectivos de una misma cohorte.
Los estudios retrospectivos suelen ser más rápidos de realizar y más baratos, pero puede ser difícil identificar las cohortes de forma correcta y que la información registrada sea completa. Además, suele ser habitual que la información sobre posibles factores de confusión no esté disponible.
Los estudios de cohortes también pueden clasificarse según usen un grupo de comparación interno o externo. Si estudiamos una cohorte poblacional general, podremos distinguir dos cohortes internas sobre la base de clasificar a los sujetos de la cohorte general en expuestos y no expuestos, según nivel de exposición. En otras ocasiones, la cohorte expuesta es seleccionada específicamente por su alta exposición. En estos casos, es preciso seleccionar una cohorte externa de sujetos no expuestos como comparación.
En tercer lugar, los estudios de cohortes pueden clasificarse en función del momento de inclusión de los sujetos en el estudio. Cuando solo se incluyen sujetos que cumplen los criterios de inclusión al comienzo del estudio, hablamos de una cohorte fija, mientras que decimos que se trata de una cohorte dinámica o abierta cuando los sujetos continúan incluyéndose a lo largo del seguimiento.
Por último, nos referiremos a un tipo especial de diseño de estudio de cohortes. En algunas ocasiones puede realizarse el estudio con una sola cohorte, en la que quiera estudiarse la incidencia o evolución de una determinada enfermedad, y cuyos resultados se comparan con datos conocidos de población general. En realidad, este estudio de cohorte única se engloba dentro de los estudios descriptivos longitudinales.
Los estudios observacionales comparten un mayor riesgo de sesgos que los experimentales, debido a la naturaleza de su diseño. Además, son susceptibles a la influencia de factores de confusión y de variables modificadoras de efecto, que no pueden equilibrarse entre las muestras de estudio, por la ausencia de aleatorización. Por este motivo, deben tenerse en cuenta todas las variables que puedan relacionarse de forma independiente con la exposición o el efecto, y considerar si han podido influir en los resultados obtenidos en el estudio.
Con todo, los estudios de cohortes son los estudios observacionales menos expuestos al efecto de errores sistemáticos, aunque pueden presentarse tanto en fase de selección como en fase de información y seguimiento.
El sesgo de selección debe considerarse siempre en los estudios de cohortes, ya que afecta a su validez, tanto interna como externa. Las dos cohortes deben ser comparables en todos los aspectos, excepto en la exposición que se está estudiando. Además, las cohortes deben ser representativas de la población de la que proceden.
Un ejemplo frecuente de sesgo es el de las cohortes formadas por voluntarios, que suelen ser poco representativas de la población general. Otra posible causa de sesgo de selección son las pérdidas que se producen durante el seguimiento, ya sean voluntarias (abandono por parte de los sujetos participantes) o involuntarias. Debe considerarse la causa de los abandonos y valorar si han podido influir en los resultados.
De manera similar a los abandonos, las pérdidas involuntarias durante el seguimiento pueden también sesgar los resultados, especialmente si están relacionadas con alguna característica de los participantes. Las pérdidas deben ser independientes de la exposición (similares en expuestos y no expuestos), ya que, de lo contrario, la validez de los resultados se verá comprometida.
Los estudios de cohortes son también vulnerables a la presencia de sesgos de información o clasificación, que están relacionados con el modo en que se recoge la información o los datos de los participantes del estudio. Se producen cuando se realiza una clasificación errónea de los participantes en el estudio en cuanto a su exposición o a la detección del efecto. Pueden deberse a errores en los procedimientos o instrumentos de medida.
El sesgo de clasificación puede ser diferencial o no diferencial. Se produce un sesgo diferencial cuando la clasificación errónea es diferente entre las cohortes, o si está relacionada con alguna de las variables implicadas en el estudio. Este sesgo influye en la validez de los resultados de forma impredecible. En ocasiones, los investigadores evalúan el efecto con más celo en un grupo que en otro, y se produce entonces el llamado sesgo del observador, con sobrestimación o infraestimación del riesgo.
Por otra parte, se produce un sesgo de clasificación no diferencial cuando el error en la clasificación se produce al azar de forma independiente a las variables del estudio. Este tipo de sesgo tiende a modificar las estimaciones del estudio en favor de la hipótesis nula, por lo que no invalida completamente los resultados, en el caso de obtenerse diferencias significativas entre las medidas de riesgo de las dos cohortes.
Por último, recordar que los estudios de cohortes son vulnerables al efecto de factores de confusión (sesgo de confusión) y de variables modificadoras de efecto (sesgo de interacción), por lo que esta posibilidad debe considerarse tanto en la fase de diseño del estudio como en la fase de análisis de los resultados, fundamentalmente mediante análisis estratificados y estudios multivariados. Ya que el procedimiento de identificación y análisis de este tipo de sesgos es similar, entre otros, al realizado con los estudios de casos y controles, lo abordaremos en el artículo correspondiente a estos estudios.
Los estudios de cohortes se caracterizan por ser estudios de incidencia, aunque la medida de frecuencia puede diferir según se trate de estudios de casos nuevos producidos durante todo el periodo de estudio (incidencia acumulada) o se tengan en cuenta el periodo de tiempo del estudio, el momento de aparición de la enfermedad y el diferente seguimiento de los grupos (tasa o densidad de incidencia).
Los conceptos de incidencia acumulada y densidad de incidencia han sido tratados en otra publicación1, por lo que no nos detendremos a detallarlos aquí. En la figuras 2 y 3 se muestra cómo calcularlos a partir de las tablas de contingencia del estudio.
Figura 2. Tabla de contingencia para el cálculo de las medidas de frecuencia y asociación en los estudios de cohortes de incidencia acumulada. Mostrar/ocultar
Figura 3. Tabla de contingencia para el cálculo de las medidas de frecuencia y asociación en estudios de cohortes de densidad de incidencia. Mostrar/ocultar
Las medidas de frecuencia utilizadas en los estudios de cohortes son los riesgos en expuestos y no expuestos, para los estudios de incidencia acumulada, y las tasas de incidencia en expuestos y no expuestos, para los estudios de densidad de incidencia. Todas ellas representan la probabilidad de desarrollar el efecto en cada una de las cohortes.
Los cocientes de las medidas de frecuencia nos proporcionan las medidas de asociación: riesgo relativo (RR), reducción absoluta del riesgo (RAR) y reducción relativa del riesgo (RRR), para los estudios de incidencia acumulada, y reducciones absoluta y relativa de las densidades de incidencia, para los estudios de tasa o densidad de incidencia. En teoría, podríamos calcular también las odds ratios o razones de prevalencia como medida de asociación, aunque suelen utilizarse menos en los estudios de cohortes y son más características de los estudios de casos y controles. En cualquier caso, ambas medidas se parecerán cuando la prevalencia del efecto estudiado sea pequeña.
El RR se define como el cociente entre el riesgo en expuestos y no expuestos, y puede tener cualquier valor entre cero e infinito. Un RR = 1 significa que el riesgo es igual en ambos grupos. Un RR > 1 significa que el riesgo es mayor en los expuestos. Por último, un RR entre cero y uno significa que el riesgo en los expuestos es menor que en los no expuestos.
La RRR es la diferencia de riesgo entre los dos grupos con respecto al grupo control o, lo que es lo mismo, cuánto aumenta o disminuye el riesgo la exposición respecto al grupo control. Más sencilla es la RAR, que no es más que la diferencia de riesgo entre expuestos y no expuestos. Ambas medidas son más utilizadas para la valoración de los resultados de los ensayos clínicos, por lo que volveremos a ellas cuando tratemos el tema.
En la figura 2 se expone el modo de calcular estas medidas de asociación. Un razonamiento similar al previo puede seguirse para calcular las reducciones absoluta y relativa de las tasas de incidencia entre expuestos y no expuestos.
Por último, podemos calcular como medidas de impacto las fracciones atribuibles en los expuestos (FAExp) y en la población (FAPob), tal como se muestra en las figuras 2 y 3.
La FAExp nos indica el número de sujetos que padecen el efecto como consecuencia directa de la exposición. De manera análoga, la FAPob nos muestra el impacto potencial de disminución del riesgo que tendría sobre la población el hecho de eliminar el factor de exposición.
Finalmente, todos los indicadores de riesgo descritos deben ser calculados con sus correspondientes intervalos de confianza. Estos intervalos nos informarán sobre la precisión de los resultados del estudio y, además, nos indicarán la existencia de significación estadística en aquellos casos en los que el intervalo de confianza no cruce la línea de efecto nulo (para RR no incluya el 1).
La principal ventaja de los estudios de cohortes es que permiten responder a preguntas clínicas sobre pronóstico en las que sería éticamente imposible plantear un ensayo clínico. Además, permiten establecer hipótesis de causalidad como paso previo a la realización de ensayos clínicos. Como ya hemos visto, permiten calcular tasas de incidencia y riesgos relativos, lo que supone una ventaja sobre los estudios de casos y controles, en los que no es posible estimar el riesgo de forma precisa por desconocerse la incidencia del efecto.
La medición de la exposición y de las variables de interés suele ser más exacta que en los estudios de casos y controles, al ser menos susceptibles al sesgo de memoria, sobre todo en los estudios prospectivos. En el caso de las cohortes retrospectivas, la calidad de la información recogida dependerá de los registros existentes y de cómo estos se adapten a los objetivos del estudio.
En general, los estudios de cohortes son menos susceptibles a la existencia de sesgos que otros estudios observacionales, y permiten estudiar el efecto de una misma exposición sobre varias enfermedades diferentes.
Entre sus inconvenientes destacan su mayor dificultad de realización y la habitual necesidad de muestras mayores, lo que conlleva generalmente costes mayores. No son eficientes para el estudio de enfermedades poco frecuentes, ya que sería necesario el seguimiento de un gran número de sujetos durante un largo periodo de tiempo para poder documentar el efecto.
Tampoco son muy útiles para enfermedades con un largo periodo de latencia, ya que conllevan largos seguimientos con riesgo de aumento de las pérdidas durante los mismos. Además, el seguimiento prolongado conlleva siempre el riesgo del cambio de los criterios de diagnóstico o de tratamiento de la enfermedad o efecto en estudio.
Por último, no debemos olvidar que, como cualquier diseño de tipo observacional, los estudios de cohortes pueden tener limitaciones para establecer relaciones de causalidad, por lo que en ocasiones son necesarios otro tipo de estudios de diseño experimental.
Molina Arias M, Ochoa Sangrador C. Estudios observacionales (II). Estudios de cohortes. Evid Pediatr. 2014;10:14.


 Artículo completo
Artículo completo
 PDF
PDF English Version
English Version