Buscando, por favor espere.
 Imprimir
Imprimir
 Añadir a biblioteca
Añadir a biblioteca
 Comentar este artículo
Comentar este artículo
Ortega Páez E, Ochoa Sangrador C, Molina Arias M. Regresión logística binaria simple. Evid Pediatr. 2022;18:11.
La regresión logística (RL) es una técnica estadística que permite relacionar una variable dependiente cualitativa (Y) con una o mas variables independientes cuantitativas y/o cualitativas (X). Dependiendo del tipo de variable dependiente, tendremos la RL binaria (cualitativa dicotómica), la RL multinomial (cualitativa categórica, con más de dos categorías) y la RL ordinal (cualitativa ordinal). En este trabajo nos centraremos en el modelo más sencillo, la Regresión logística simple binaria.
La RL actualmente, como todas las técnicas de regresión, está englobada dentro del modelo lineal generalizado (MLG) que responde a la fórmula:
$$Función(y)\space=\space a\space +\space bx_1\space + \space cx_2 \space +...+\space nx_n\space +\space e. $$
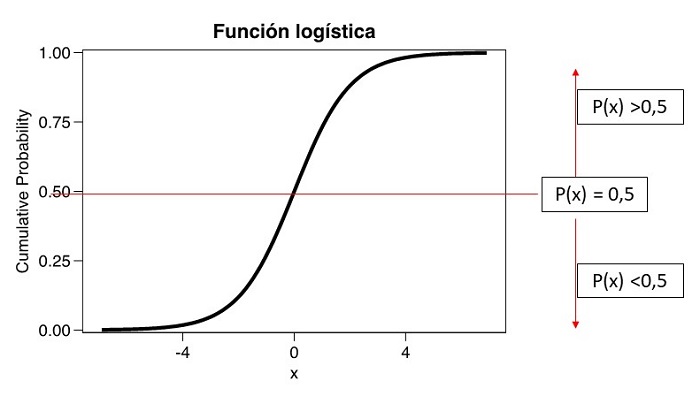
Si la variable dependiente es categórica, Y = 0 sería ausencia del carácter e Y = 1 presencia del mismo. A diferencia de la regresión lineal que predice los valores medios que toma la variable dependiente, la RL predice probabilidades (p) de ocurrencia del suceso en función del valor que toman las variables independientes, siendo sus valores desde 0 a 1. Matemáticamente es posible aplicar el modelo de regresión lineal de mínimos cuadrados, pero sus valores no serían creíbles, puesto que, para valores extremos del predictor, se obtienen valores de Y menores que 0 o mayores que 1. Esto contradice los valores que debe tomar una probabilidad (0,1). Para resolver este problema debemos buscar una función que transforme el valor devuelto por la regresión lineal en un resultado comprendido entre 0 y 1. Aunque hay varias funciones, la función logística o sigmoide (figura 1), que cumple estos requisitos, responde a la siguiente ecuación:
$$\\p(x)={1\over {1+e^{-z}}}$$
Figura 1. Función logística. Mostrar/ocultar
Como se puede ver en la figura 1, la curva logística se caracteriza porque valores de probabilidad de Y >0,5 se clasifican como 1 o presencia del evento y probabilidades Y <0,5 se clasifican como 0 o no presencia del mismo, siendo el P(Y) = 0,5 el punto de corte.
Despejando z en la ecuación logística tenemos:
$$\\p(x) + p(x)e^{-z}=1 → p(x)e^{-z}=1-p(x) $$
$$\\e^{-z}= {1-p(x)\over p(x)} → e^{z}={p(x)\over 1-p(x)}=Odds.$$
Si tomamos logaritmos neperianos (ln) a ambos de la igualdad tenemos:
$$\\ln\space e^z=Z=ln {p(x)\over 1-p(x)}=β_0 + β_1→\bf{ln\space(odds)= β_0 + β_1x}.$$
Al final hemos conseguido expresar en ln de odds el modelo lineal, mucho más sencillo de manejar ya que sigue la distribución normal. A esta transformación se le llama logit.
Una vez vista la función logística, siendo la variable Y binaria (1/0), la media de los valores de Y para cada posible valor de X sigue una función logística, expresada en la siguiente ecuación
$$\\P(Y/X)= {1\over {1+e^{-(β_0+β_1x)}}}+ε={exp\space(β_0+β_1x)\over {1+exp\space{(β_0+β_1x)}}}.$$
β0 y β1 son los coeficientes del modelo de regresión y el término ε representa el error residual.
La regresión logística es una técnica robusta y necesita pocos requisitos, básicamente son:
La estimación de los parámetros se realiza por el método de máxima verosimilitud, que consiste en calcular los valores de los coeficientes de regresión que dan a la muestra observada la máxima probabilidad posible. Este proceso es aproximado y se hace por varias iteraciones. Obviamos la explicación del proceso de estimación por exceder el objetivo de este documento. El lector interesado puede informarse en la bibliografía referenciada.
Una vez estimados los coeficientes del modelo, debemos comprobar hasta qué punto explica la variación de la variable dependiente. Existes varios procedimientos.
Se trata de conocer como reproduce el modelo la probabilidad pronosticada. Se realiza por dos tipos de contrastes, el contraste que analiza la bondad de ajuste global del modelo y el contraste de bondad de ajuste cuando se introduce la variable independiente.
La verosimilitud del modelo representada por l (likelihood), nos dice la probabilidad de reproducir los datos de la muestra a partir del modelo. Como este número es muy pequeño (entre 0 y 1), es más ventajoso trabajar con el logaritmo neperinano (LL), que como es un número negativo se suele expresar en -2LL, que es positivo. Desviación o lejanía (deviance) es el grado de ajuste del modelo a los datos y viene dada por el valor del estadístico -2LL y cuanto más pequeño sea el valor mayor ajuste existirá.
Se realiza a partir la verosimilitud del modelo. También llamada prueba de Omnibús (-2LR). Se compara la verosimilitud del modelo nulo o null que sólo tiene la constante (-2LL0) con el modelo que contiene la variable predictora (-2LLM) que sigue una distribución χ2 con el número de grados de libertad equivalente al número de variables (p). Es similar a la prueba F global de la ANOVA utilizada en regresión lineal.
$$\\-2LR=-2LLO-(-2LLM)→\spaceχ^2_{gl=p}.$$
La hipótesis nula (H0) = asume que todos los coeficientes del modelo sin la constante son igual a cero. Si p <0,05, rechazamos la hipótesis nula de igualdad de coeficientes y supondremos que el modelo estimado es significativo en cuanto a la relación entre ambas variables y presenta una buena bondad de ajuste.
Prueba de bondad de ajuste de Hosmer-Lemeshow. Valora la concordancia que existe entre las probabilidades observadas en la muestra y las predichas por el modelo, sigue una distribución χ2. Bajo la hipótesis nula de que no existen diferencias entre ambas probabilidades, una p <0,05 concluye que rechazamos que exista una bondad de ajuste del modelo. Tiene el inconveniente, que cuando algún valor esperado de muy pequeño (<5) no se computa el estadístico y toma el valor 0, pudiéndose concluir erróneamente que existe bondad de ajuste.
La alternativa a este estadístico es la prueba de verosimilitud vista en el epígrafe anterior.
Otra forma de evaluar la bondad del ajuste a partir de la idea de que un valor alto de la probabilidad predicha se asociará con un resultado de 1 en la variable dependiente y un valor bajo cercano al cero con el 0. Podríamos utilizar el modelo como clasificación de una prueba diagnóstica, calculando su sensibilidad, especificidad y exactitud. Un valor mayor del 75% nos diría que el modelo presenta un buen ajuste.
Para medir el grado de varianza explicada por el modelo ajustado, se han desarrollado métodos que por analogía con la R2 de la regresión lineal se denominan genéricamente PseudoR2. Toman valores entre 0 y 1, cuanto mayor es el valor, mayor es la varianza explicada. No se trata de una prueba para medir la bondad de ajuste propiamente dicha.
$$\\R^2_{MF}= 1-{l(0)\over l(M)}.$$
$$\\R^2_c= 1-({l(0)\over l(M)})^{2\over n};\space n=\space tamaño\space muestral.$$
Nos indica la proporción de varianza explicada por la variable predictora (independiente). Tiene el inconveniente que nunca toma el valor 1, aunque el modelo explique el 100% de la variabilidad de la variable de respuesta.
$$\\R^2_N= 1-{R^2\over R_{máx}^2};\space R^2_{máx}= 1-l(0)^{2\over n}.$$
Veamos un ejemplo utilizando un programa de acceso libre, el software estadístico R (https://www.r-project.org/) con el plugin RCommander (https://estadistica-dma.ulpgc.es/cursoR4ULPGC/12-Rcommander.html) y la base de datos GEA_ped.RData, disponible en la web de Evidencias en Pediatría. Si necesita saber cómo instalar RCommander, puede consultar el siguiente tutorial en línea (http://sct.uab.cat/estadistica/sites/sct.uab.cat.estadistica/files/instalacion_r_commander_0.pdf). El ejercicio se ha realizado con la versión de RStudio Versión 1.1.463 para Mac y RCommander v 2.7.1 en inglés.
En la base de datos se recoge un estudio transversal de 256 niños sobre algunos factores de riesgo asociados con diarrea aguda (bacteriana o no bacteriana). Nos centraremos en estudiar si la variable sangre en heces (sangre_heces) codificada como dicotómica (0 = no, 1 = sí) está asociada a gastroenteritis bacteriana (gea_bacteriana) codificada como dicotómica (0 = no, 1 = sí).
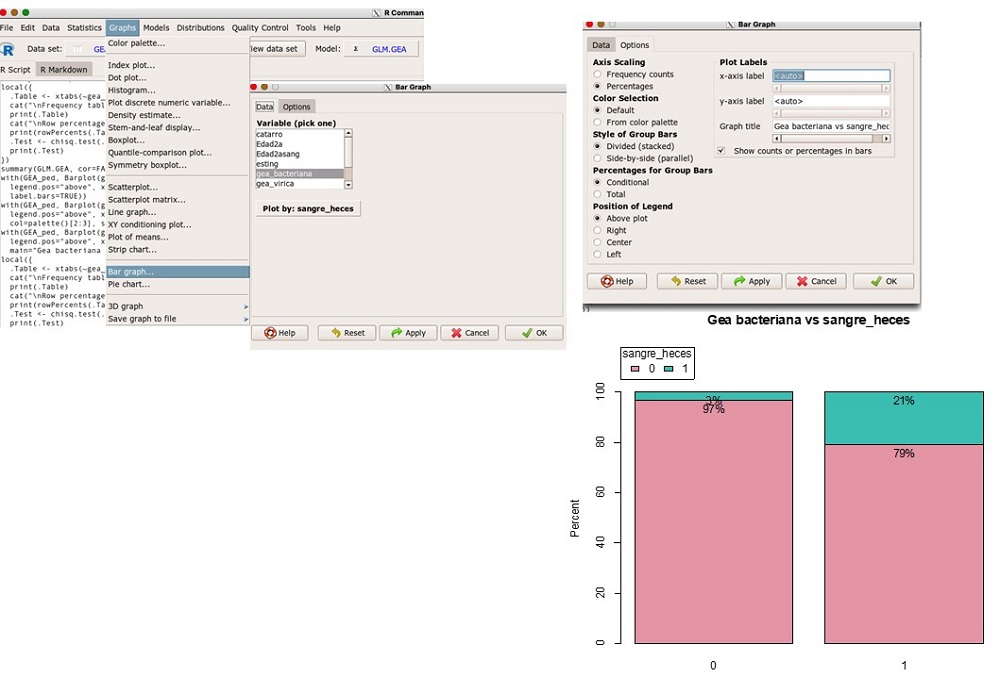
En primer lugar, veremos la distribución de frecuencias de sangre en heces en las gastroenteritis agudas (GEA) bacterianas y no bacterianas. Para ello seleccionamos la opción Graph (gráficos)→ bar graph (gráfico de barras). En la ventana emergente seleccionamos en la pestaña de data, gea_bacteriana y plot by: sangre_heces (estratificado por sangre en heces), en la pestaña options (opciones) percentages en la primera casilla y el resto por defecto. Obtenemos que el 21% de las GEA bacterianas presentan sangre en heces frente a no bacterianas (figura 2). Podemos deducir que puede existir una relación entre sangre en heces y GEA bacteriana.
Figura 2. Gráfico de frecuencias entre GEA bacteriana y sangre en heces. Mostrar/ocultar
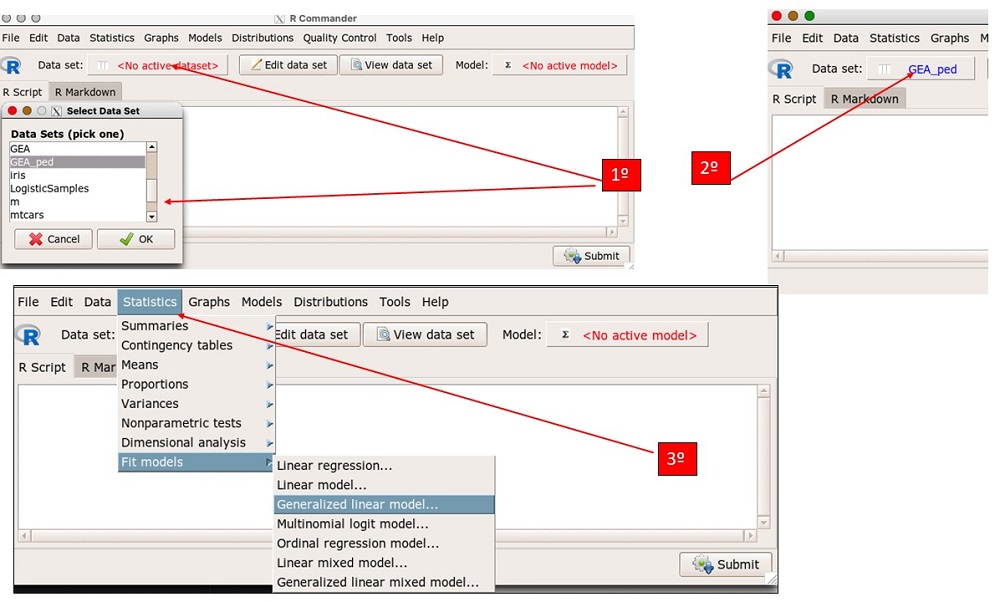
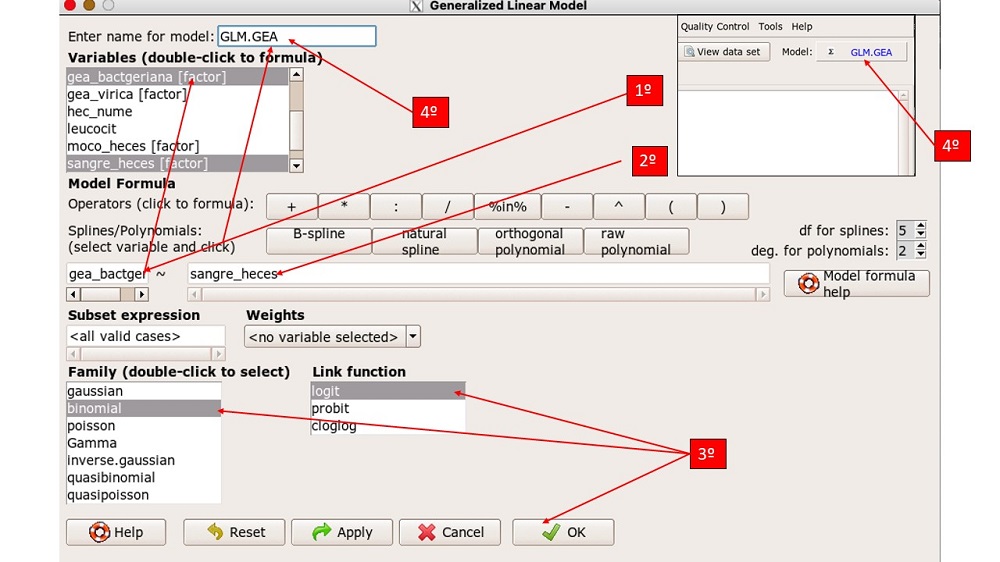
En primer lugar, tenemos que activar la base de datos (GEA_ped) una vez cargada en la pestaña “No active data set” (base de datos no activada) y seleccionarla en la ventana emergente inmediatamente nos aparecerá la base activa. Seguidamente en la pestaña statistics (estadísticos)→ fit models (ajuste de modelos) → Generalized linear model (modelo lineal generalizado) y aceptamos (figura 3). Como ya se dijo, R Commander incluye dentro de los modelos lineares generalizados todo modelo de regresión. Seguidamente nos aparece un cuadro de diálogo común para cualquier modelo de regresión, en la que primeramente tenemos las variables a seleccionar, la fórmula de regresión y por último la función del modelo. En nuestro caso, seleccionamos gea_bacteriana como variable dependiente en la primera casilla de la fórmula, sangre_heces en la casilla de la derecha, en family →binomial (la distribución de probabilidad de la variable dependiente es binomial) y en link function→logit, le damos un nombre al modelo (GLM.GEA) para poder después identificarlo, aceptamos y nos aparece el modelo activo en la pestaña de model (figura 4).
Figura 3. Construcción de un modelo de regresión logística (I). Mostrar/ocultar
Figura 4. Construcción de un modelo de regresión logística (II). Mostrar/ocultar
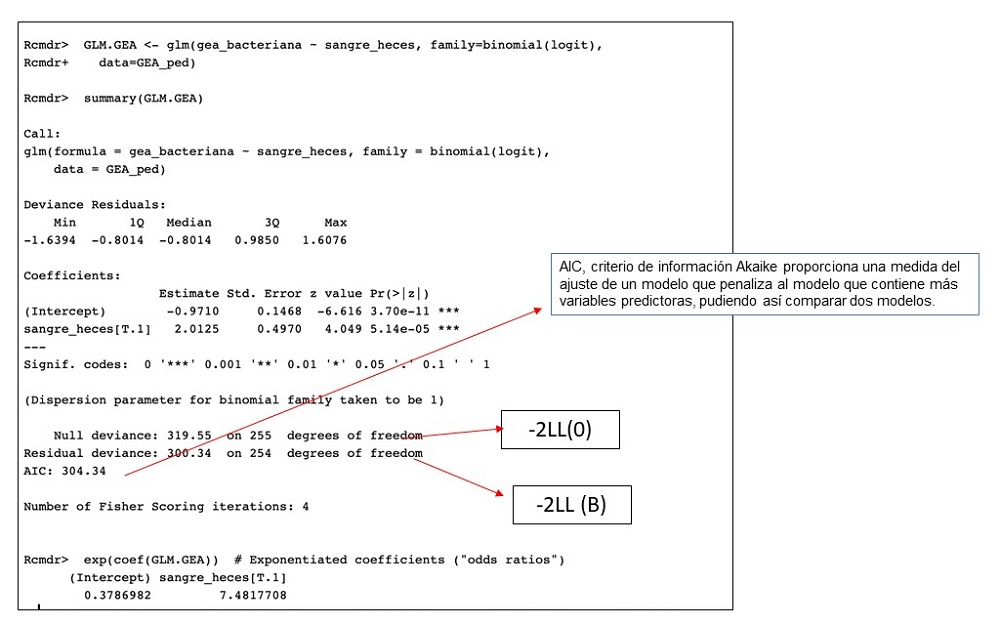
En la ventana de salida de datos (figura 5) R nos muestra en primer lugar la fórmula utilizada para hacer la regresión, función glm, la variable dependiente primero y la independiente después, la distribución (binomial), la función (logit) y la base de datos. Posteriormente los residuos de las desviaciones (deviance residuals) por cuantiles, interpretados como la contribución de cada dato a la deviance total. En segundo lugar, los coeficientes de regresión (coeficcients), el termino constante (Intercept), y la variable independiente (sangre_heces, con la categoría analizada presencia de sangre en heces -T.1) que es la única que interpretamos, ya que es la que contribuye a la explicación del modelo. De izquierda a derecha tenemos el valor puntual estimado (2.01) que, al ser positivo, nos dice que existe una relación positiva, el error estándar (0,49), la prueba de significación de Wald (z: 4,049), que en este caso se ha realizado por aproximación a la normal, al ser un tamaño muestral suficientemente grande, y, por último, el nivel de significación (p = 0,00005); el programa nos señala con tres asteriscos que la p < 0,0001.
Figura 5. Resultados de un modelo de regresión logística. Mostrar/ocultar
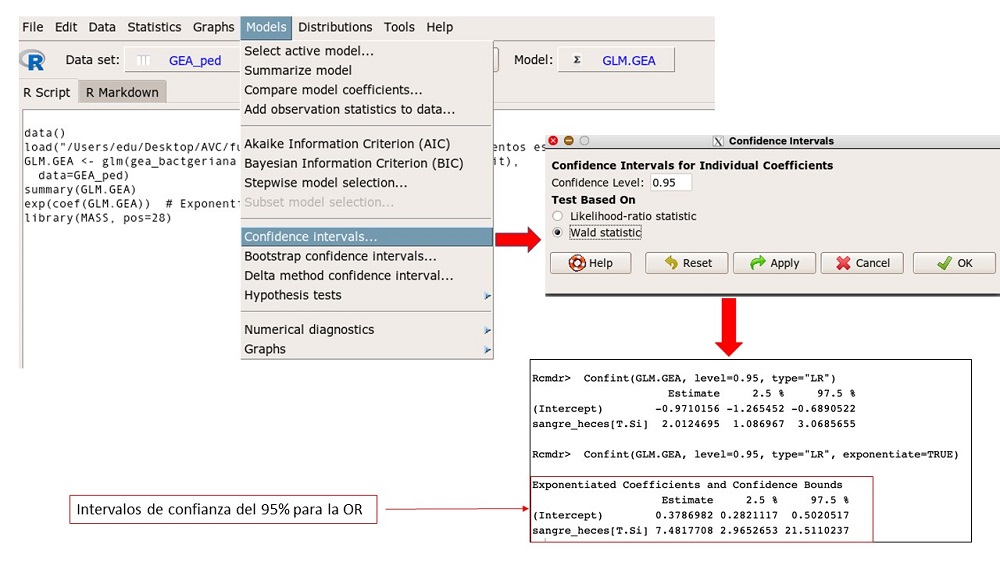
Posteriormente R nos muestra las desviaciones que ahora veremos, el valor del criterio de información de Akaike (AIC), que valora el mejor modelo ajustado cuando existen varios modelos a valorar (que será el de menor AIC), y el valor puntual de la OR de sangre en heces = 7,48. Para conocer los intervalos de confianza del 95% (IC 95) de la OR debemos ir a la pestaña models (modelos) → confidence intervals (intervalos de confianza) y se nos despliega una ventana en la que podemos elegir el método para construir el IC 95; recomendándose el de Wald para muestras grandes y el likehood ratio para muestras pequeñas. Elegimos el de Wald, el más utilizado, ya que ambos darán resultados muy similares. Obtenemos un IC 95 de la OR de 2,9 a 21,5 (figura 6).
Figura 6. Intervalos de confianza para la OR. Mostrar/ocultar
La interpretación sería, que existe relación con un nivel muy alto de significación entre la presencia de sangre en heces y la GEA bacteriana, esto supone que por término medio es 7 veces más probable presentar GEA bacteriana si existe sangre en heces que si no existe (OR = 7,48, IC 95: 2,9 a 21,5).
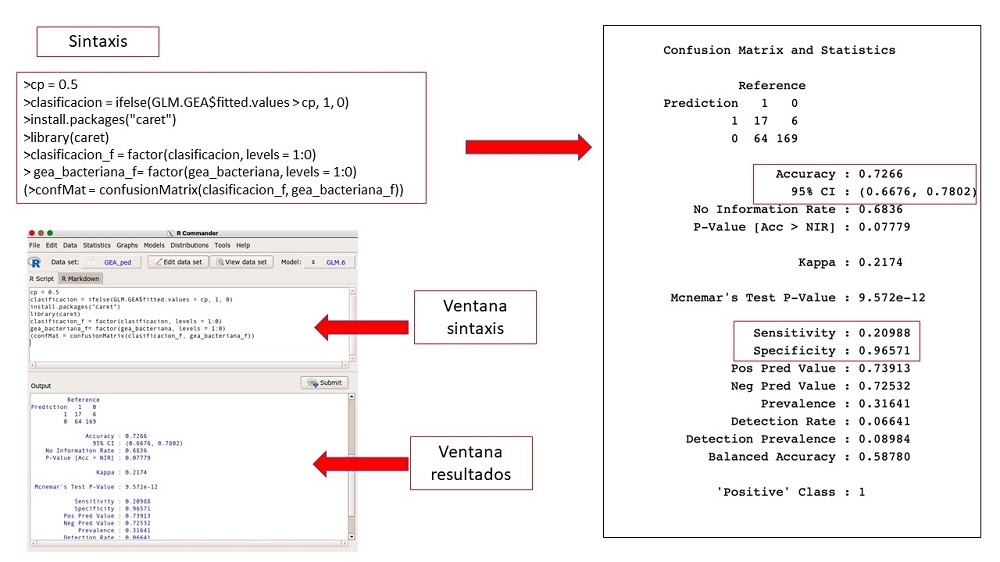
R no nos ofrece la sensibilidad, especificidad y exactitud el modelo, para conocerla tenemos que recurrir a comandos de sintaxis. Conociendo que el punto de corte es 0,5 (cp = 0,5), clasificamos (clasificación) todos los valores mayores de 0,5 como 1 (cp > 0,1). Colocamos en la variable clasificación y en la variable gea_bacteriana los 1 para que estén en la columna 1 y los 0 en la columna 2. Aplicamos la función “confusionMatrix” de la librería caret (figura 7). Como podemos ver, el modelo clasifica correctamente al 72,6% de los valores (accuracy: 0,726; IC 95: 0,66 a 0,78) con una sensibilidad 20% y una especificad del 96%. El modelo nos dice que la presencia de sangre en heces predice escasamente la diarrea bacteriana, su ausencia prácticamente la descarta.
Figura 7. Sensibilidad, especificidad y exactitud de un modelo logístico. Mostrar/ocultar
Vimos anteriormente que en la figura 5 se ofrecen los resultados de la deviance del modelo solo con la constante, LL0 (null deviance) 319,55 y la deviance del modelo con la variable independiente LLB (residual deviance) 300,24. Ambos valores son mediocres, ya que están alejados de 0 que sería el ajuste perfecto, pero existe una disminución del modelo LLB lo que indica un mejor ajuste al introducir la variable sangre_heces en el modelo.
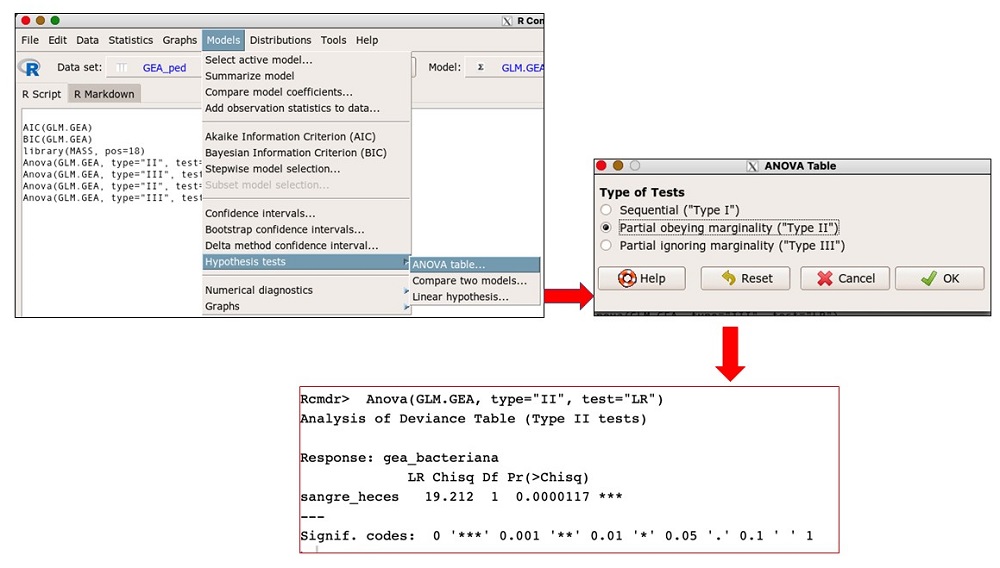
Para conocer si la bondad de ajuste es significativa realizamos la prueba de bondad de ajuste global u ómnibus del modelo. R ofrece esta prueba bajo el nombre ANOVA table, por similitud con la F de la ANOVA de regresión lineal pero una prueba χ2. Una vez seleccionado el modelo (GLM.GEA), en la pestaña models (modelos) tenemos una serie de opciones para estudiar el ajuste del modelo. Seleccionamos Hypothesis test (test de hipótesis) →ANOVA table (tabla ANOVA) y en la ventana emergente seleccionamos la segunda opción y aceptamos. R nos ofrece en la ventana de resultados el valor de la prueba (χ2 = 19,12; gl = 1) con una significación muy alta (p = 0,0000117) (figura 8).
Figura 8. Prueba de ajuste global u Omnibús. Mostrar/ocultar
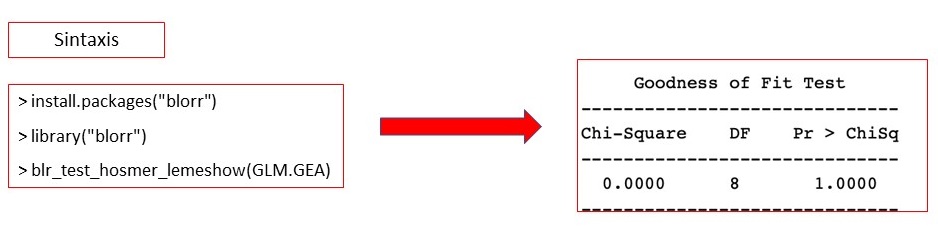
Si queremos conocer la prueba de Bondad de ajuste global de Hosmer-Lemeshow, debemos hacerla mediante sintaxis, ya que R Commander no la tiene implementada, usando la función blr_test_hosmer_lemeshow de la librería blorr, como se detalla a continuación (figura 9). Nos ofrece resultados parecidos a la prueba de ómnibus, p <0,00001.
Figura 9. Prueba de bondad de ajuste de Hosmer-Lemeshow. Mostrar/ocultar
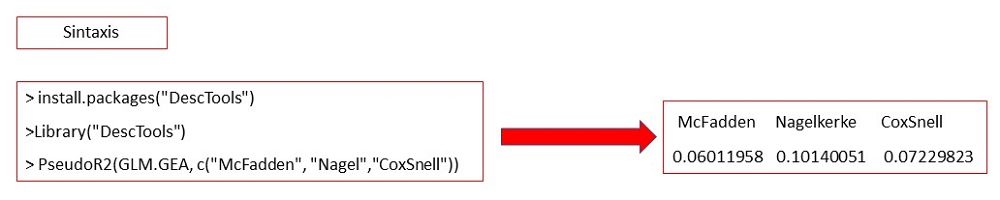
Para obtener las pseudoR2, igualmente hay que recurrir a los comandos de sintaxis con la librería DescTools y la función PseudoR2 (figura 10).
Figura 10. Pseudo R2. Mostrar/ocultar
Podemos observar que el modelo GLM.GEA explica el 10% de la varianza de la GEA bacteriana (R2 Nagelkerke).
Una de las utilidades del modelo logístico es realizar predicciones sobre la presencia o ausencia del suceso en la variable dependiente, siempre y cuando el diseño epidemiológico sea adecuado (longitudinal). En nuestro ejemplo, podemos calcular la probabilidad de presentar gastroenteritis bacteriana en presencia de sangre en heces.
$$\\ P\space(GEA\space bacteriana/sangre\space en\space heces) ={1\over {1+e^{-(-0,97+2,01)}}}={1\over {1+e^{-1,04}}}= {1\over {1+0,35}}=0,74$$
El modelo predice que en presencia de sangre en heces existe una probabilidad del 74% de presentar GEA bacteriana.
Como resumen, podemos distinguir varias etapas en la RL:
Ortega Páez E, Ochoa Sangrador C, Molina Arias M. Regresión logística binaria simple. Evid Pediatr. 2022;18:11.


 Artículo completo
Artículo completo
 PDF
PDF English Version
English Version