Buscando, por favor espere.
 Imprimir
Imprimir
 Añadir a biblioteca
Añadir a biblioteca
 Comentar este artículo
Comentar este artículo
Ortega Páez E, Ochoa Sangrador C, Molina Arias M. Representación gráfica de variables. Evid Pediatr. 2019;15:13.
En este capítulo, tercero y último de la serie de estadística descriptiva, hablaremos de la representación gráfica de las variables. En Medicina y Epidemiología cada vez es más frecuente el uso de métodos gráficos para exponer los datos. Son fáciles de comprender y en un solo vistazo dan al investigador una primera información para comprender la distribución de los datos: una imagen vale más que mil palabras. Pero el abuso de las gráficas y el mal uso puede tergiversar la percepción del lector, haciéndole cometer errores de interpretación. Este capítulo tiene la intención de dar pautas para realizar de forma correcta la representación gráfica de las variables para evitar errores. Para ello, hemos utilizado el software R (https://www.r-project.org/), por dos razones. La primera es que es de libre disponibilidad en varias plataformas Windows, Mac y Linux, y en segundo lugar por su relativa sencillez de manejo y gran versatilidad. Los lectores de este trabajo pueden, si quieren, reproducir de aquí en adelante los ejemplos tratados descargando la aplicación desde The Comprehensive R Archive Network (https://cran.r-project.org/) o la versión para Windows en español (http://knuth.uca.es/R/R-UCA), así como la base de datos de este capítulo ** ir enlace Base de datos gráficos*.
Los gráficos adecuados son aquellos que sean capaces de plasmar sus características. Cuantitativas continuas, si muestran un número infinito de valores, y cuantitativas discretas si muestran un número finito.
Los gráficos más usuales son el histograma, el diagrama de tallo y hoja y el diagrama de cajas.
Es el más usado, porque es sencillo de interpretar. Se construye representando en el eje de abscisas (X) los valores agrupados de la variable en intervalos, se fijan sus límites y se construyen tantos rectángulos como intervalos haya, cuya área debe ser proporcional a la frecuencia. En el eje de ordenadas (Y) los valores de las frecuencias de la variable en términos absolutos o relativos. La amplitud de los intervalos no tiene que ser constante, pero la mayoría de las veces lo es: en este caso, las alturas de los rectángulos serán proporcionales a su frecuencia.
Para ilustrar este capítulo se ha construido una base de datos ficticia que incluye distintos tipos de variables (figura 1). Hemos utilizado para realizar los gráficos, como se ha indicado antes, el software R, con la librería Rcommander (http://knuth.uca.es/R/doku.php?id=instalacion_de_r_y_rcmdr:r-uca), que convierte al programa en una interfaz mediante menús fácilmente manejable (figura 2).
Figura 1. Base de datos ficticia, con variables. Mostrar/ocultar
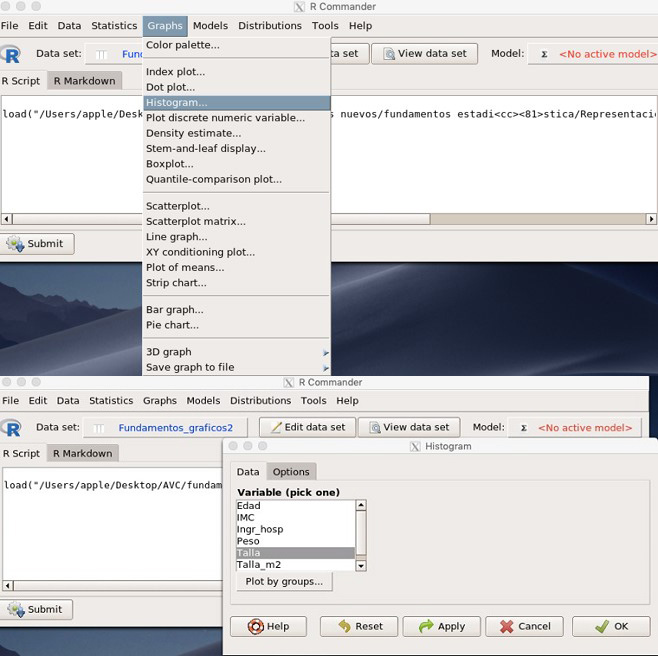
Figura 2. Capturas de Rcommander. Mostrar/ocultar
En nuestro caso hemos utilizado la versión para Mac (OX) (https://www.rcommander.com/). En el anexo 1 se describen los pasos utilizados en R para cada gráfico.
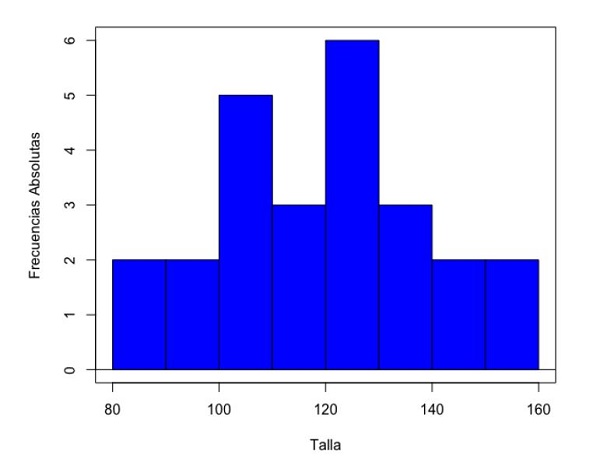
Veamos el primer ejemplo. En la figura 3 podemos ver el histograma para la variable “Talla”. Podemos ver que se ha dividido en ocho intervalos de clase de 10 cm, el que tiene mayor frecuencia es el comprendido entre 120-130 cm, con seis sujetos.
Figura 3. Histograma de la variable “Talla”. Mostrar/ocultar
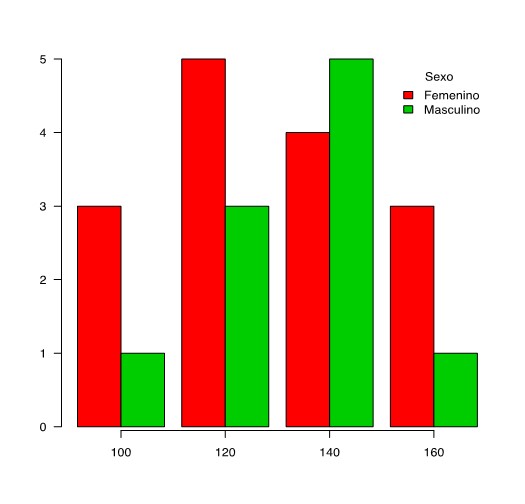
Figura 4. Distribución de la talla según el sexo. Mostrar/ocultar
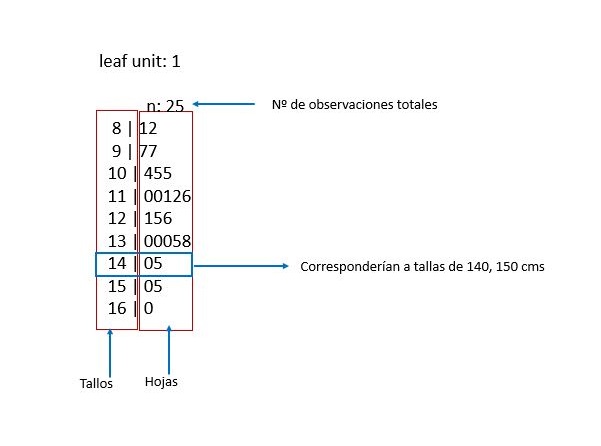
En la figura 5 podemos ver la representación de la variable “Talla”. En la primera columna se representan los tallos (que corresponden en nuestro caso al primer digito) y en la segunda las hojas (en este caso el segundo digito). Es un diagrama híbrido entre una tabla (información ordenada) y una gráfica (parecida al histograma). Tiene la ventaja de no perder información individual, identifica la distribución de los datos (posible media y mediana) y si existen clases faltantes. Esto hace que para muchos autores sea la representación gráfica de elección.
Figura 5. Gráfica de tallo y hoja de la variable “Talla”. Mostrar/ocultar
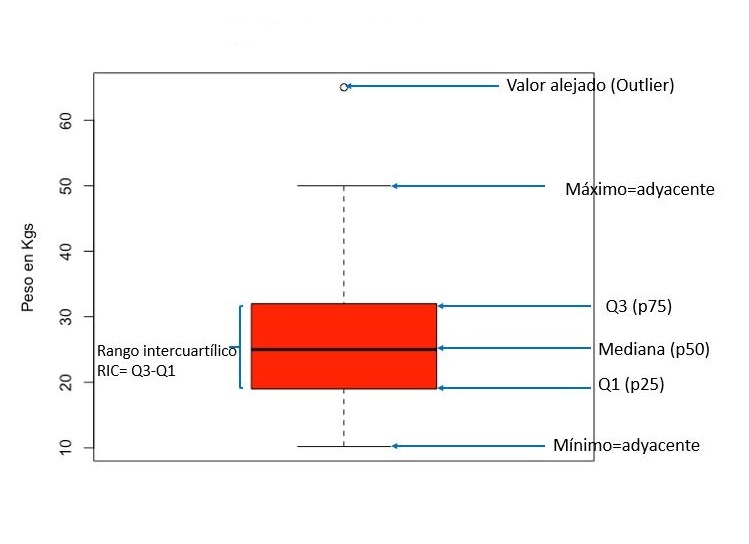
Es un tipo de gráfico que se usa frecuentemente para representar los estadísticos descriptivos. Consiste en representar la distribución de los datos mediante una caja cuyo límite superior es el percentil 75 o tercer cuartil (Q3), el inferior es el percentil 25 o primer cuartil (Q1) y el centro es la mediana (percentil 50). Desde los extremos de la caja se prolongan unos “bigotes”, que son los limites superior e inferior de la distribución (valores adyacentes), cuyo valor no pude ser más de 1,5 veces el rango intecuartílico (RIC, distancia entre Q1-Q3). Los valores más allá de los adyacentes se denominan valores alejados (outliers) y muestran los valores máximos o mínimos reales de la distribución. En la figura 6 representamos el boxplot de la variable “Peso”.
Figura 6. Distribución de la variable “Peso”. Mostrar/ocultar
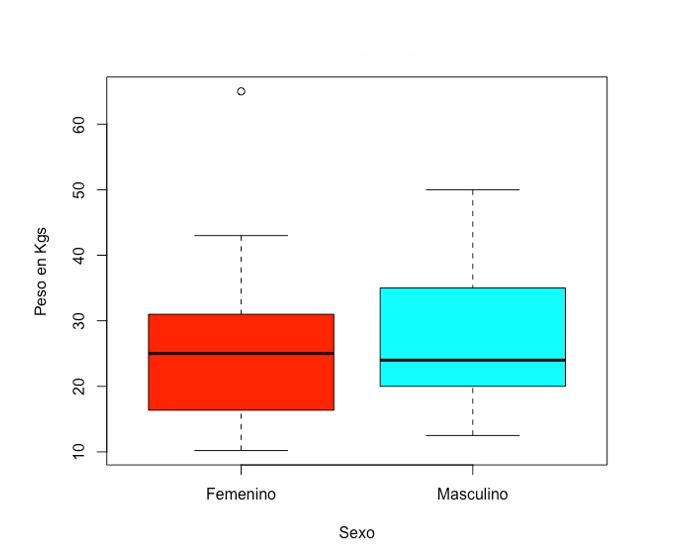
Esta representación gráfica tiene varias ventajas: nos informa de la asimetría de la distribución, de los valores máximo y mínimo, detecta valores alejados, puede comparar dos o varias distribuciones, como se muestra en la figura 7, donde podemos comprobar que la distribución de los datos en el peso del sexo masculino, aunque de mediana muy parecida al femenino es más asimétrico (caja más ancha e irregular).
Figura 7. Distribución de peso por sexo. Mostrar/ocultar
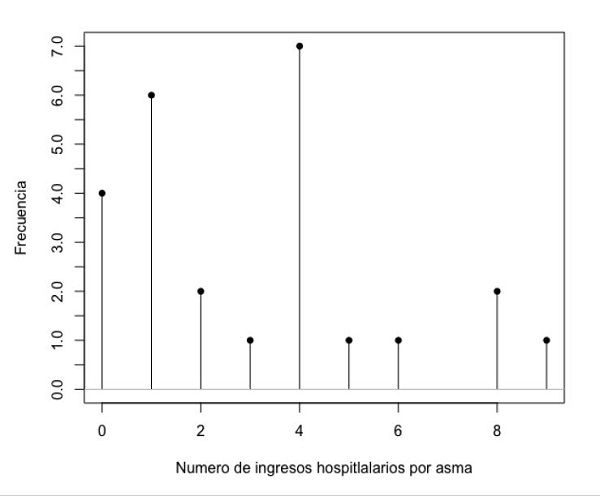
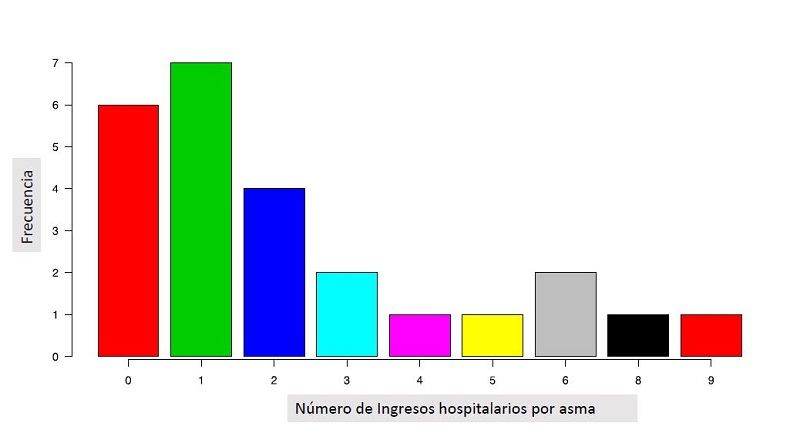
R dispone de un tipo de gráficos especial (discrete plot) para variables discretas, de líneas verticales, de tal forma que en abscisas representamos el valor de la variable y en ordenadas la frecuencia absoluta. En nuestro ejemplo, vemos el resultado de la variable “Número de ingresos” de la figura 8, donde observamos que el mayor número de ingresos son cuatro y que se corresponde con siete pacientes. Alternativamente también se puede representar por grafico de barras (figura 9), como vemos posteriormente, donde podemos observar los mismos resultados.
Figura 8. Distribución de la variable “Número de ingresos por asma”. Mostrar/ocultar
Figura 9. Distribución de la variable “Número de ingresos hospitalarios por asma”. Mostrar/ocultar
Existen dos tipos de representaciones gráficas bien diferenciadas, según sean variables cualitativas categóricas nominales u ordinales. La primera se representa por el gráfico de sectores (pie chart) y la segunda por el gráfico de barras (bar chart).
Ya se ha adelantado que la representación adecuada es por medio del gráfico de sectores o circular. Consiste en representar mediante un círculo la distribución de las categorías, donde cada sector representa una categoría y cuya área es directamente proporcional a su frecuencia, con lo que se consigue que los sectores más grandes correspondan con las categorías que presenten mayor frecuencia, esto hace fácilmente reconocible la distribución de los datos mediante un vistazo. Su construcción es muy sencilla, si el total de los datos equivale a 360 grados de la circunferencia, multiplicando la frecuencia relativa de cada variable por 360 grados obtenemos los grados de cada sector.
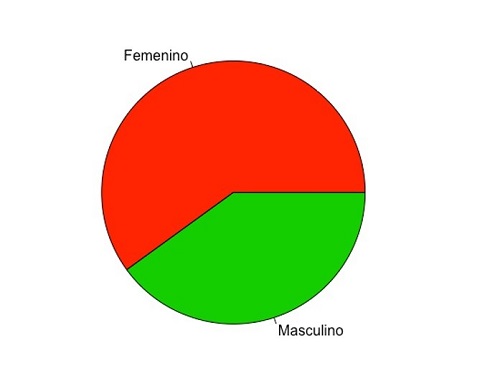
En nuestro ejemplo, la variable “Sexo” tiene un total de 25 observaciones, de las que 15 son del femenino y 10 del masculino, que corresponden a las frecuencias relativas de 0,6 (15/25) y 0,4 (10/25), respectivamente, y esto equivale a 216 grados (0,6 × 360) para el sector femenino y 144 grados para el masculino (0,4 × 360). En la figura 10 se representa el gráfico de sectores de la variable “Sexo”. Podemos ver claramente cómo la categoría del sexo femenino tiene mayor frecuencia que la del masculino. Existen gráficos sectoriales en 3D, separados por categorías, pero, a nuestro modo de ver, cuando existen varias categorías (más de siete) pueden ser difíciles de interpretar.
Figura 10. Distribución de la variable “Sexo”. Mostrar/ocultar
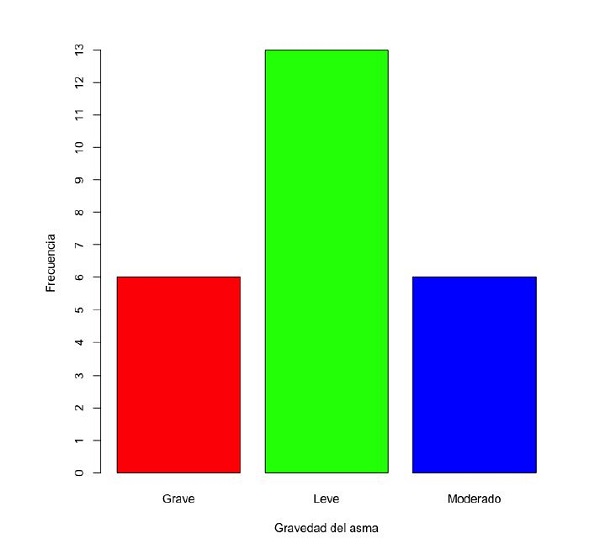
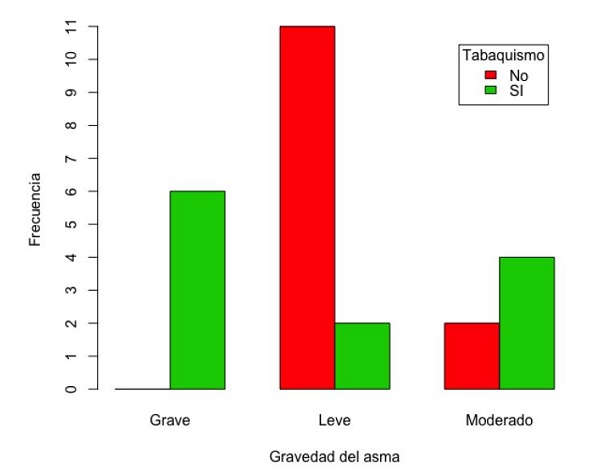
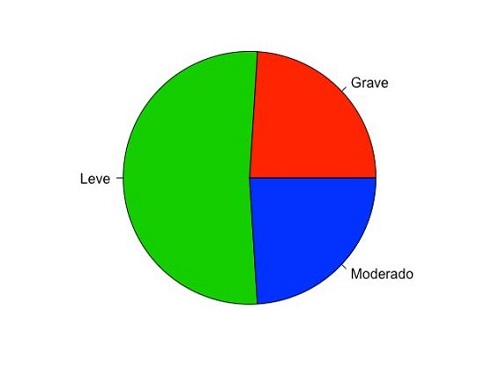
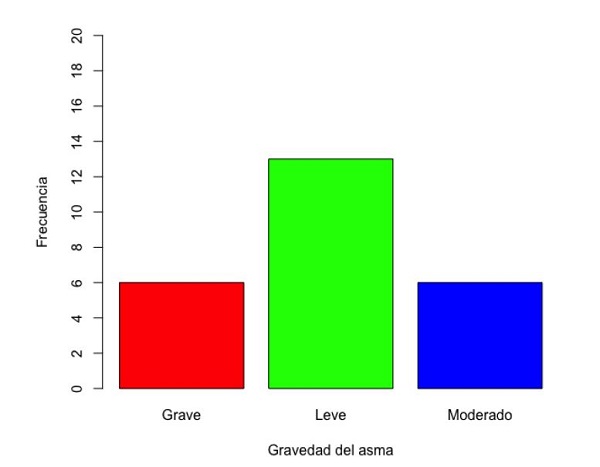
Este tipo de variables debe representarse mediante el gráfico de barras (bar chart), para que los atributos de orden o jerarquía de las categorías no se pierdan. En nuestro ejemplo, la variable “Asma” se corresponde con la gravedad del asma y consta de tres categorías ordinales: leve, moderada y grave, representado en la figura 11. Observamos cómo la categoría de mayor frecuencia es la de asmáticos leves. Este tipo de gráficos permite estratificar una variable ordinal por otra categórica, en nuestro caso la gravedad del asma según el tabaquismo familiar (figura 12), donde podemos observar que el asma leve es más frecuente en los que no presentan tabaquismo familiar. A nuestro juicio, es un error representar las variables ordinales mediante el grafico de sectores, ya que, aunque podamos saber qué categoría tiene la mayor frecuencia, se pierde su jerarquía (figura 13). Este tipo de gráficos es fácilmente manipulable para aumentar o disminuir espuriamente las diferencias; en nuestro caso hemos “trucado” la variable cambiando simplemente la escala del eje de ordenadas, consiguiendo disminuir el efecto de las diferencias entre categorías (figura 14).
Figura 11. Distribución de la variable “Gravedad del asma”. Mostrar/ocultar
Figura 12. Distribución de la variable “Gravedad del asma según tabaquismo”. Mostrar/ocultar
Figura 13. Distribución de la variable “Gravedad del asma”. Mostrar/ocultar
Figura 14. Distribución de la variable “Gravedad del asma” Mostrar/ocultar
Para terminar, queremos resumir los errores más frecuentes en el uso de los gráficos:
Para cargar base de datos, cargar Rcommander → menú Data → Load data set → buscar Base datos gráficos descargada del enlace y cargarla:
Ortega Páez E, Ochoa Sangrador C, Molina Arias M. Representación gráfica de variables. Evid Pediatr. 2019;15:13.


 Artículo completo
Artículo completo
 PDF
PDF English Version
English Version