Buscando, por favor espere.
 Imprimir
Imprimir
 Añadir a biblioteca
Añadir a biblioteca
 Comentar este artículo
Comentar este artículo
Ochoa Sangrador C, Ortega Páez E, Molina Arias M. Inferencia estadística: estimación por intervalos. Evid Pediatr. 2019;15:40.
En artículos previos de esta serie dijimos que podemos diferenciar dos estrategias para realizar inferencia estadística: la estimación por intervalos y el contraste de hipótesis. En este artículo revisaremos la primera de ellas: la estimación por intervalos. Debemos recordar que, para estimar cualquier parámetro poblacional, recurrimos a muestras; si las muestras han sido seleccionadas de forma aleatoria y son suficientemente grandes, los resultados van a ser representativos de lo que ocurre en la población, pero siempre van a tener cierto grado de error por imprecisión. Del análisis de los resultados de nuestra muestra obtendremos una estimación puntual (por ejemplo, media, proporción, diferencia de medias, diferencia de proporciones, etc.), que será solo una de las múltiples estimaciones puntuales teóricas, obtenidas del análisis de otras posibles muestras seleccionadas a partir de la población.
Por ello la forma más prudente de facilitar cualquier estimación es presentarla como un rango de valores entre los que puede estar el parámetro poblacional a estimar. Este rango constituye lo que denominamos “intervalo de confianza”. Habitualmente estimamos intervalos con un 95% de confianza, que interpretaremos como que el parámetro poblacional tiene una probabilidad del 95% de encontrarse dentro de esos límites.
Para estimar los intervalos de confianza partiremos de las estimaciones puntuales de nuestra muestra, habitualmente, una frecuencia relativa (proporción) para una variable nominal dicotómica, o con una media (media muestral) para una variable continua, que son nuestras mejores aproximaciones al parámetro poblacional que hay que estimar: una proporción (π) o una media (μ). Pero como han sido estimadas en muestras, por prudencia, solo podemos decir que los parámetros a estimar tendrán valores cercanos a los que hemos obtenido en nuestra muestra.
Pero ¿cómo calculamos el intervalo de error alrededor de nuestras medidas muestrales? La aproximación más intuitiva es intentar saber si las proporciones o medias muestrales siguen algún tipo conocido de distribución de probabilidad.
Hagamos un ejercicio teórico a partir de los datos de una amplia muestra de casos reales de partos (12 000), de la que vamos a seleccionar muestras de creciente tamaño muestral. Nuestro objetivo es estimar la proporción de partos distócicos que hay en esa población. No olvidemos que incluso con muestras de gran tamaño muestral, las muestras solo son aproximaciones a la población. Asimismo, recordemos que, en el mundo real, este ejercicio teórico no es posible, ya que en nuestros estudios solo vamos a contar con una única muestra (que podría ser la que aquí vamos a usar como población).
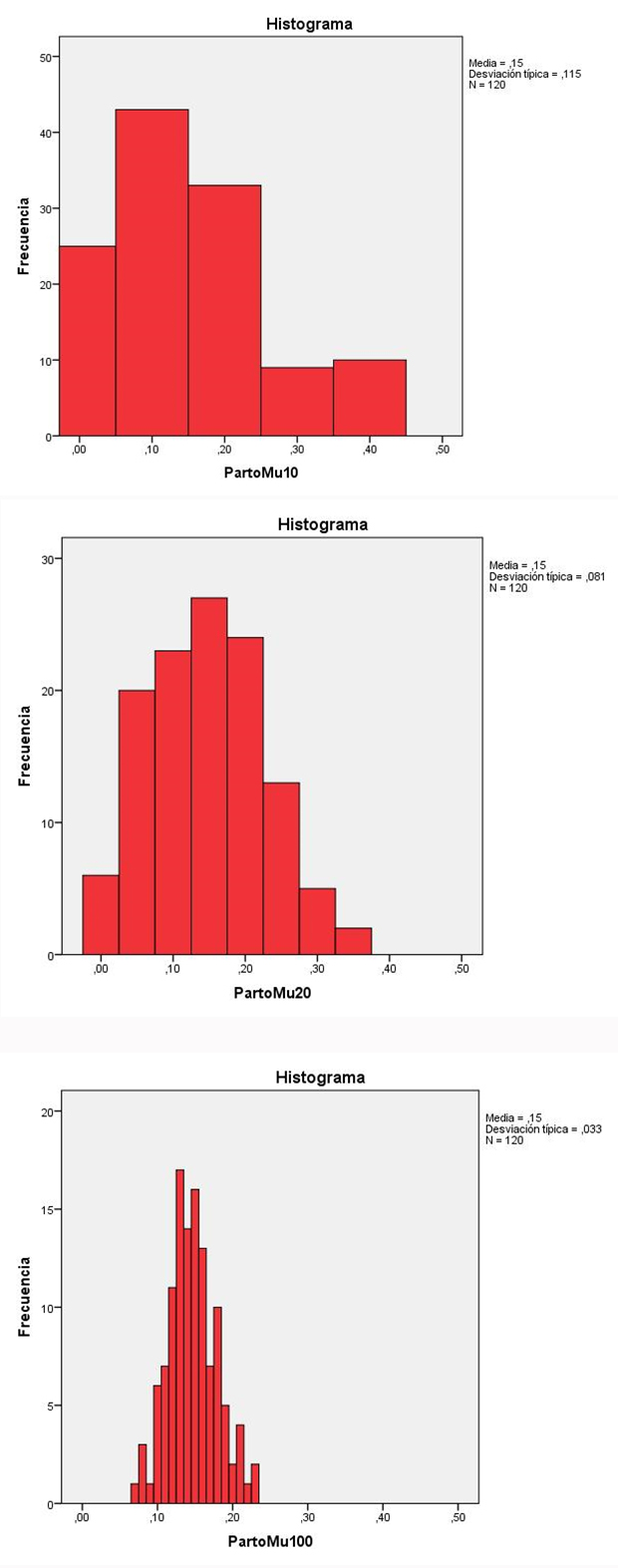
Hemos seleccionado 120 muestras aleatorias de tamaño n = 10 (cada muestra 10 partos). En cada una de las 120 muestras estimamos la frecuencia relativa de parto distócico, con lo que obtendremos 120 proporciones, que utilizaremos como si fueran observaciones individuales, que adoptarán valores entre 0 y 1, para confeccionar un histograma de frecuencias (figura 1). Como la proporción de partos distócicos en la muestra que hemos empleado como población es 0,15 (15%), la mayoría de los valores van a ser 0,10 y 0,20; es importante advertir de nuevo que esa información que sabemos aquí es siempre desconocida. Junto al histograma podemos ver la media y desviación típica de esas observaciones, que han pasado a ser consideradas como variables continuas. Nos dice que la media es 0,15 y la desviación típica 0,115.
Figura 1. Histogramas de frecuencia de las proporciones de partos distócicos en 120 muestras de tamaños n = 10, n = 20 y n = 100. Mostrar/ocultar
Ahora vamos a seleccionar 120 muestras aleatorias de tamaño n = 20 (cada muestra 20 partos). Haciendo el mismo procedimiento obtenemos un nuevo histograma de frecuencias, con estimaciones de media 0,15 y desviación típica 0,081.
Finalmente vamos a seleccionar 120 muestras aleatorias de tamaño n = 100 (cada muestra 100 partos). Haciendo el mismo procedimiento obtenemos un nuevo histograma de frecuencias, con estimaciones de media 0,15 y desviación típica 0,033.
En los histogramas (figura 1) podemos ver que, aunque el valor teórico poblacional era 0,15 (en el conjunto de los 12 000 partos) las proporciones de partos distócicos en las muestras individuales son muy variables, aunque la media de todas las proporciones coincide.
Podemos ver también, cómo a mayor tamaño muestral los valores obtenidos son menos dispersos, lo que se traduce en un histograma más estrecho, con una apariencia cada vez más acampanada, y en una desviación típica progresivamente menor (0,115; 0,081; 0,033). Curiosamente se puede deducir que el factor que pondera dicha dispersión es el tamaño muestral siguiendo una relación fija: raíz cuadrada del cociente de la proporción (0,15) por su complementario (0,85) y dividido por el tamaño de las muestras (10 o 20 o 100):
$$\sqrt {\frac {0,15\space x\space 0,85}{10}} = 0,1112\space\space\space \sqrt {\frac {0,15\space x\space 0,85}{20}} = 0,080\space\space\space \sqrt {\frac {0,15\space x\space 0,85}{100}} = 0,035$$
Esta relación corresponde a lo que conocemos como error estándar o error típico, que se comporta como el factor de dispersión (desviación típica) de la distribución de proporciones muestrales, que al igual que otros estimadores sigue una distribución normal (según el teorema del límite central para muestras n ≥30). El error estándar se puede calcular a partir de la proporción que hemos encontrado en nuestra muestra, su complementario (1-p) y el tamaño muestral (la aproximación a la normal es válida si el producto [n × p × 1-p] es mayor que 5).
$$\ Error\space estándar_{proporción} = \sqrt {\frac {p\space x\space (1-p)}{n}}$$
Dijimos al comienzo de este apartado que nuestro objetivo era estimar un parámetro poblacional, pero no sabíamos cómo cuantificar nuestra incertidumbre para dar los valores entre los que es verosímil que se encuentre. Ahora ya tenemos los elementos que necesitamos para estimar el parámetro poblacional a partir de las medidas descriptivas de nuestra muestra. Como solo vamos a tener una muestra, asumiremos la proporción observada como el punto central de la estimación (estimación puntual). Utilizando esa proporción y el tamaño muestral calcularemos el error estándar y utilizando las propiedades de la distribución normal, podemos cuantificar entre qué rango de valores se encuentra.
Imaginemos que hemos realizado un estudio con una muestra de 100 partos y que hemos encontrado una proporción de 0,17 (17 de los 100, 17%, tuvieron parto distócico). Lo más probable es que hubiéramos encontrado un 15%, pero por azar hemos encontrado otro resultado cercano. Asumimos ese 0,17 como media y calculamos el error estándar con la fórmula:
$$\ Error\space estándar_{proporción} = \sqrt {\frac {0,17\space x\space (1-0,17)}{100}}=0,0375$$
En un artículo previo de esta serie vimos que en una distribución de probabilidad normal el rango entre 1,96 (Z1-α/2) veces por debajo y por arriba de la media se encontraban el 95% de los valores. Usemos esta propiedad para estimar el rango de valores entre los que tengo una confianza del 95% de que se encuentre la proporción poblacional. Este cálculo corresponde a:
$$p±Z_{1-∝/2} \space x\space error\space estándar >> 0,17 ± 1,96\space x\space 0,0375.$$
$$IC\space 95\space (proporción\space poblacional\space “π”):\space 0,0965\space a\space 0,2435\space (9,65\space a\space 24,35\%).$$
Habitualmente este rango se conoce como intervalo de confianza del 95% (IC 95). Se puede interpretar diciendo que tenemos un 95% de confianza de que la proporción poblacional se encuentre entre 9,65 y 24,35% (con un error menor del 5%). Aunque esta es la interpretación más sencilla, la interpretación real corresponde a que, si hiciéramos 100 estudios con un tamaño muestral similar al nuestro, el verdadero parámetro poblacional estaría incluido en 95 de los 100 intervalos de confianza estimados.
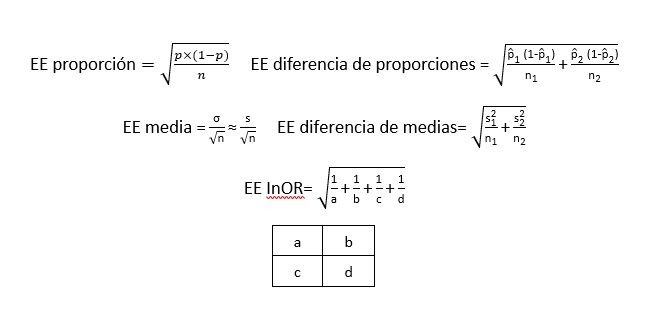
Al igual que hemos deducido la fórmula del error estándar para la estimación de proporciones, el lector interesado puede consultar en textos especializados la deducción de las fórmulas de error estándar de otros parámetros. Lo importante es entender que ese error estándar es el factor de dispersión del conjunto teórico de estimaciones de dicho parámetro en sucesivas muestras (figura 2).
Figura 2. Fórmulas de estimación de errores estándar de algunos parámetros poblacionales. Mostrar/ocultar
El procedimiento siempre es el mismo: 1) calculamos la medida descriptiva o la medida de frecuencia, riesgo o impacto de nuestra muestra; 2) estimamos a partir de dichos datos el error estándar, y 3) usamos dicho error estándar y el valor Z correspondiente (para un intervalo de confianza del 95%: 1,96) para estimar el intervalo de confianza.
Cuando manejemos variables continuas, definidas por sus medias y desviaciones típicas, no debemos confundir la desviación típica de nuestra muestra, que describe nuestros datos, con el error estándar, que nos permite estimar el rango de error en la estimación de la media poblacional.
Aunque el cálculo para proporciones, medias, diferencias de proporciones o diferencias de medias resulta sencillo, no recomendamos hacer dichos cálculos de forma manual. Para ello tenemos calculadoras epidemiológicas que realizan los cálculos fácilmente o, si tenemos los datos tabulados, podemos recurrir a paquetes estadísticos.
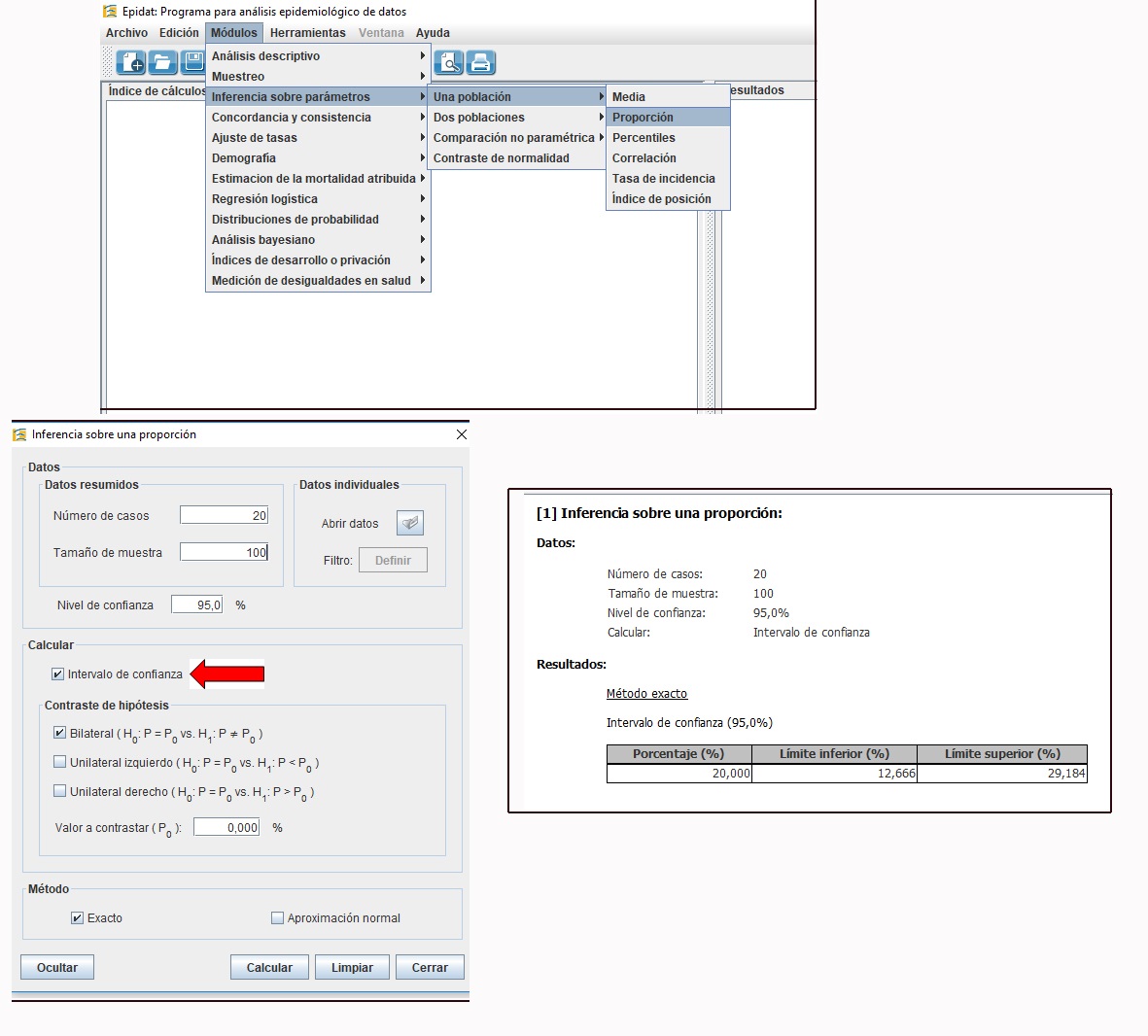
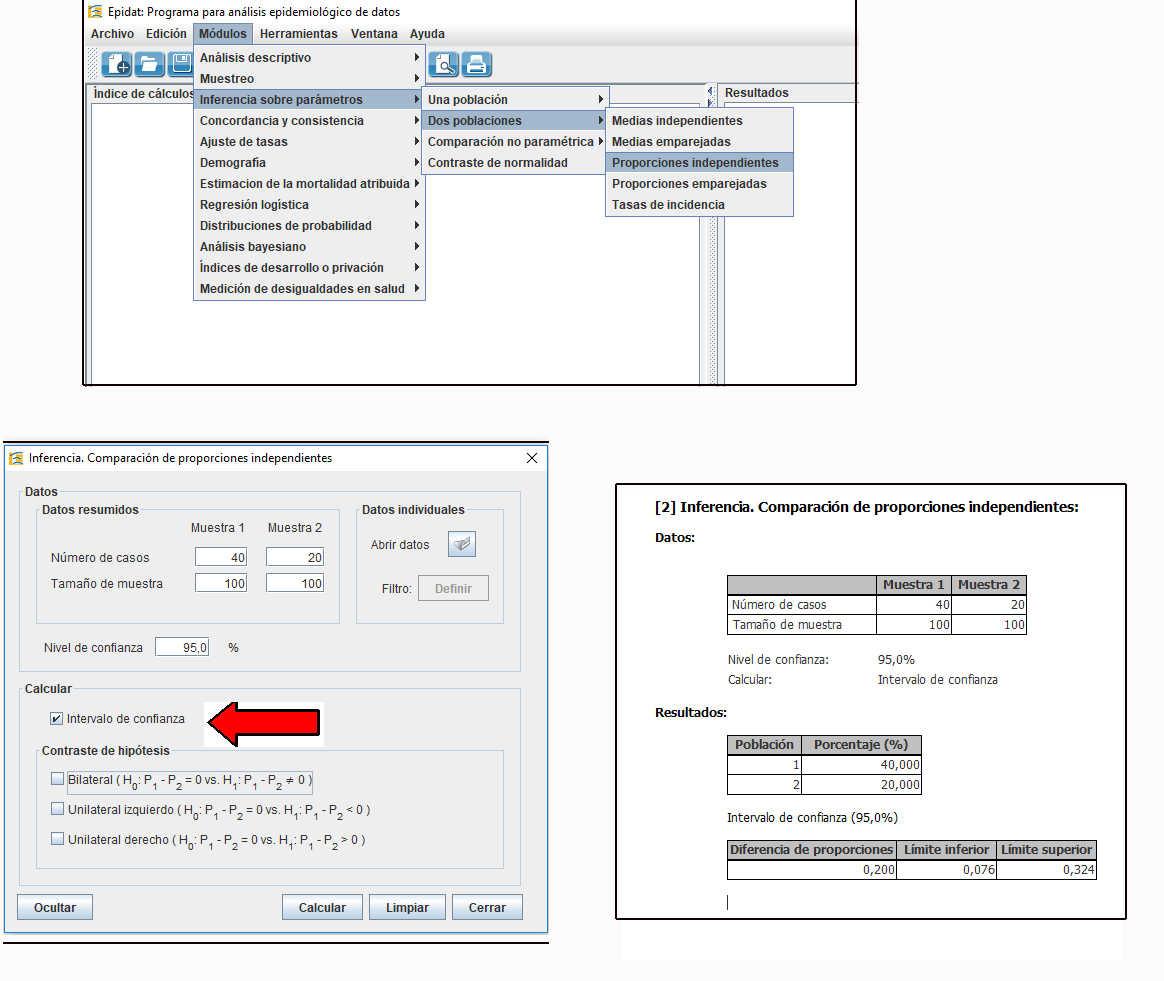
En la figura 3 se presenta un ejemplo de cálculo de intervalo de confianza para una proporción y en la figura 4 para una diferencia de proporciones. Ambos cálculos se han realizado con el programa Epidat 4.2, software gratuito que puede ser descargado libremente (https://www.sergas.es/Saude-publica/EPIDAT-4-2?idioma=es) y que no requiere instalación (el fichero descargado se puede ejecutar).
Figura 3. Cálculo de un intervalo de confianza para una proporción con Epidat 4.2. Se presenta el menú desplegado en el que se accede a la ventana correspondiente (en “Calcular”, debe señalarse exclusivamente la opción de intervalo de confianza) y los resultados. Mostrar/ocultar
Figura 4. Cálculo de un intervalo de confianza para una diferencia de proporciones con Epidat 4.2. Se presenta el menú desplegado en el que se accede a la ventana correspondiente (en Calcular, debe señalarse exclusivamente la opción de intervalo de confianza) y los resultados. Mostrar/ocultar
El intervalo de confianza de la proporción 20% (20/100) de la figura 3, se sitúa entre el 12,66 y el 29,18%. Esto es, tenemos un 95% de confianza de que la proporción poblacional se encuentre en este intervalo.
El intervalo de confianza de la diferencia de proporciones (40-20%= 20%) de la figura 4, se sitúa entre 0,076 (7,6%) y 0,324 (32,4%). Esto es, tenemos un 95% de confianza de que la diferencia de proporciones poblacional se encuentre en este intervalo. Aunque esto supone adelantarnos a lo que se abordará en próximos artículos sobre contraste de hipótesis, la información que nos da el intervalo de confianza, nos permite decir que la muestra 1 tiene mayor porcentaje que la muestra 2 (imaginemos que fuera éxito de tratamiento), porque en el intervalo de confianza no está incluido el 0% (valor nulo que indica ausencia de diferencias), con un riesgo de error menor del 5% (p <0,05).
Ochoa Sangrador C, Ortega Páez E, Molina Arias M. Inferencia estadística: estimación por intervalos. Evid Pediatr. 2019;15:40.


 Artículo completo
Artículo completo
 PDF
PDF