Buscando, por favor espere.
 Imprimir
Imprimir
 Añadir a biblioteca
Añadir a biblioteca
 Comentar este artículo
Comentar este artículo
Molina Arias M, Ortega Páez E, Ochoa Sangrador C. Estudios de supervivencia. Método de Kaplan-Meier. Evid Pediatr. 2022;18:20.
Vimos en una entrada anterior de esta serie que las variables pueden clasificarse, en sentido general, como cuantitativas (continuas o discretas) o cualitativas (formadas por dos o más categorías excluyentes entre sí).
Sin embargo, existen situaciones en las que nos interesa medir el tiempo que pasa hasta que se produce determinado suceso. Pensemos que nos interesa saber cuánto tarda en producirse un suceso o evento después de una intervención, el tiempo que pasa hasta que se manifiesta determinado síntoma, la duración de la eficacia de un tratamiento, etc.
En estos casos, no nos basta con conocer únicamente si los participantes del estudio presentan el suceso, sino que estamos interesados en manejar los datos sobre el tiempo transcurrido. Así, utilizaremos las llamadas variables de tiempo a suceso, que tienen dos componentes. El primero es un componente dicotómico, que nos dirá si el suceso se produce o no. El segundo es un componente cuantitativo, que es el tiempo transcurrido hasta la producción del suceso. Para el estudio de este tipo de variables emplearemos los denominados estudios de supervivencia.
Aclaremos que, aunque se llamen de supervivencia, el suceso en estudio no tiene por qué ser obligatoriamente la muerte, sino que puede ser cualquier acontecimiento de nuestro interés que, en general, solo puede ocurrir una vez durante el estudio.
En un estudio de cohortes o un ensayo clínico podemos determinar cuántos de los participantes han desarrollado el evento al final del estudio, utilizando así las medidas de asociación habituales o estableciendo un modelo de regresión, lineal o logística, en función del tipo de variable dependiente. Para esto se precisa que todos los sujetos comiencen y terminen el periodo de seguimiento de una forma similar.
Sin embargo, cuando estamos interesados en conocer también el tiempo que tarda en producirse el suceso, tendremos que enfrentar dos inconvenientes.
El primero, la variable que queremos modelizar es el tiempo, que no sigue una distribución normal, por lo que no podríamos utilizar técnicas como la regresión lineal. El segundo, suele ser habitual que no todos los participantes tengan el mismo periodo de seguimiento y que el estudio termine sin que observemos el suceso de estudio en todos ellos.
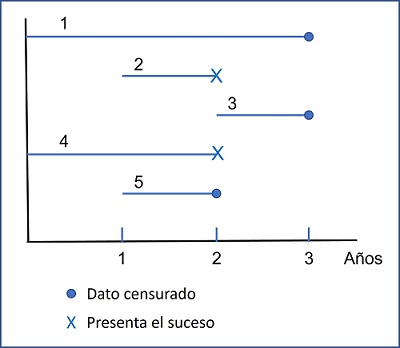
Veamos como ejemplo la figura 1, que representa el recorrido de cinco pacientes a lo largo del periodo de duración de un estudio de tres años, cuya variable de resultado es la mortalidad. El primer participante se incorpora al comienzo del estudio y llega al final sin haber presentado el suceso. El segundo comienza al año y fallece un año después. El tercero comienza a los dos años y sigue vivo al final del estudio. El cuarto comienza desde el principio del estudio y fallece dos años después. Por último, el quinto se incorpora al final del primer año y se pierde después de un año de seguimiento.
Figura 1. Seguimiento desigual de los diferentes participantes en el estudio. Mostrar/ocultar
El abordaje simplista sería calcular la supervivencia en función del número de eventos y el número de sujetos del estudio. En este ejemplo, fallecen 2 de 5, luego la supervivencia sería del 60%. Este método sería incorrecto por dos motivos. El primero, ignora el hecho del seguimiento desigual de los participantes. El segundo no tiene en cuenta la información de los participantes que no fallecen o que abandonan el estudio de forma precoz, que podrían haber presentado el suceso de haberse prolongado el periodo de seguimiento.
Así, cuando realizamos un estudio de supervivencia, algunos participantes habrán presentado el suceso de interés antes de finalizar el estudio, pero el resto también nos proporcionará información parcial sobre el tiempo transcurrido hasta que el suceso no se había producido. Estas observaciones son los datos censurados.
Un participante puede terminar el estudio por tres situaciones:
El dato del tiempo de seguimiento hasta el último momento en que sabemos que no se ha producido el suceso es un dato censurado. Así, son todos datos censurados excepto los tiempos de los que presentan el evento en cuestión. Teniendo esto en cuenta, se define el tiempo de supervivencia como el periodo transcurrido desde la fecha del comienzo del seguimiento hasta la fecha del último contacto, bien por presentar el suceso (momento en que sale del estudio) o por haber sido censurado.
Existen diversas metodologías para el estudio de datos de supervivencia, entre ellas dos técnicas no paramétricas que son las curvas de Kaplan-Meier y la regresión de Cox. Trataremos el primer método a continuación y dejaremos la regresión de Cox para un artículo posterior.
El método de Kaplan-Meier nos permite estimar la curva de supervivencia. Como ya hemos dicho, se trata de un método no paramétrico que no presupone que los datos sigan una distribución particular, sino que solo requiere que los sujetos censurados se hubiesen comportado del mismo modo que los seguidos hasta la producción del evento o, dicho de otra forma, que la censura sea no informativa.
Si se da el caso de que el hecho de retirar un participante del estudio antes de tiempo (censurar) proporciona de manera indirecta información sobre su pronóstico, hablaremos de censura informativa. No importa que haya muchos participantes censurados en el estudio, pero es fundamental que esta censura sea no informativa.
Para estimar la proporción de los pacientes que sobreviven durante un tiempo determinado deberemos tener en cuenta, no solo el número total de participantes y sobrevivientes, sino también la información proporcionada por los datos censurados. Para esto, tendremos que elaborar una tabla que calcule la probabilidad de sobrevivir para cada periodo de tiempo, con lo que podremos estimar la probabilidad de supervivencia individual a lo largo del tiempo y al final del periodo de estudio. Veamos un ejemplo para entenderlo mejor.
Tabla 1. Tabla de supervivencia. Mostrar/ocultar
En la tabla 1 vemos representado un estudio con 100 participantes y un periodo de seguimiento de 5 años. En cada fila de la tabla podemos observar los participantes que quedan ese año (N), los que son censurados en ese periodo (C), los que fallecen (M), la probabilidad de mortalidad en ese periodo (PM), la probabilidad de supervivencia parcial en ese periodo (PSP) y la probabilidad de supervivencia global desde el inicio hasta ese periodo (PSG).
En el primer año se produce una muerte y se censuran dos participantes. La PM es de 0,01, luego la PSP y PSG (coinciden en el primer periodo) es de 0,99.
En el segundo año contamos con 97 participantes (restamos el fallecido y los dos censurados durante el periodo anterior). Se observan dos muertes y se censuran tres. La PM será de 2/97 = 0,02, luego la PSP será del 0,98. Para calcular la PSG tendremos que calcular la probabilidad combinada de sobrevivir al periodo anterior y de sobrevivir al actual, lo que haremos multiplicando las probabilidades de supervivencia de los dos periodos. Así, PSG al final del segundo año será de 0,98 × 0,99 = 0,97.
Al inicio del tercer año tendremos 92 participantes (restamos los tres censurados y dos fallecidos del periodo anterior). En este periodo se producen cinco fallecimientos y no hay ningún dato censurado. Podemos calcular PM = 0,05, PSP = 0,95 y PSG = 0,95 × 0,97 = 0,92.
Y, de manera similar, procesaríamos toda la tabla hasta llegar al último periodo, que nos permitirá afirmar que la supervivencia global a los cinco años es de 0,89 (89%).
Finalmente, con los datos de esta tabla podremos representar gráficamente la curva de supervivencia o curva de Kaplan-Meier, como veremos a continuación.
Veamos un ejemplo utilizando un programa de acceso libre, el software estadístico R (https://www.r-project.org/) con el plugin RCommander (https://estadistica-dma.ulpgc.es/cursoR4ULPGC/12-Rcommander.html) y la base de datos EeP_Fund_SupervivenciaT12m.RData, disponible en la web de Evidencias en Pediatría. Si necesita saber cómo instalar RCommander, puede consultar el siguiente tutorial en línea (http://sct.uab.cat/estadistica/sites/sct.uab.cat.estadistica/files/instalacion_r_commander_0.pdf).
En la base de datos se recogen una serie de registros sobre la duración de la lactancia materna en un grupo de madres con sus hijos, además de otras variables como peso del recién nacido, edad, tipo de parto, nivel de educación, etc. Dos variables tienen especial relevancia para el ejemplo que nos ocupa: la duración en meses de la lactancia materna durante el periodo de seguimiento de un año (LactDuracionHasta12m) y la variable lactancia materna al final del periodo (LactanMenos12mes), que se codifica como 0 en el caso de persistir la lactancia materna y como 1 en el caso de haberse interrumpido antes del final del estudio.
La instalación básica de RCommander no incluye las rutinas para realizar las técnicas de análisis de supervivencia, por lo que, antes de empezar, debemos cargar un plugin (una extensión) denominado RcmdrPlugin.survival.
Una vez que hemos abierto el programa R, debemos instalar el paquete correspondiente al plugin (si no se ha instalado y usado antes), para lo cual el método más rápido es teclear el comando install.packages(RcmdrPlugin.survival). Si este método falla, puede seleccionarse en R el menú Paquetes → Instalar paquetes(s)… y seleccionar un CRAN de la lista que ofrece la ventana emergente. Una vez hecho, veremos la lista de todos los paquetes de R ordenados alfabéticamente. Buscamos y marcamos RcmdrPlugin.survival y pulsamos OK.
Una vez cargado el plugin, podemos lanzar directamente RCommander con el plugin habilitado mediante el comando library(RcmdrPlugin.survival).
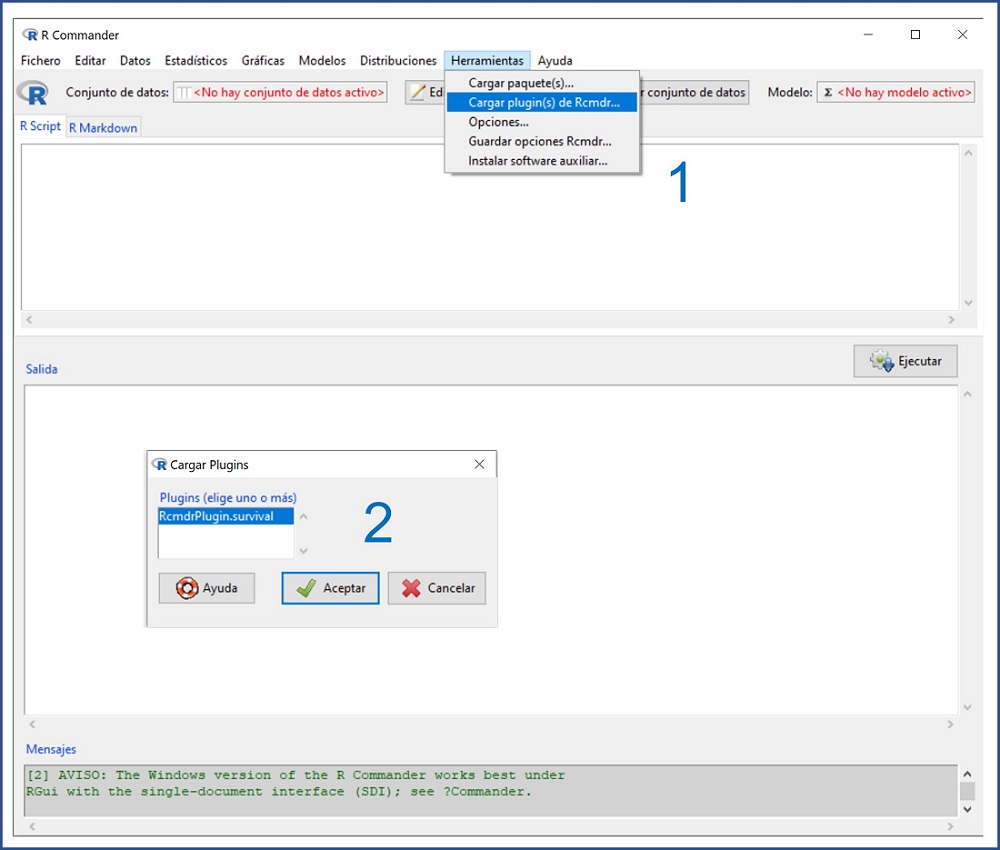
Otra forma alternativa es, después de cargar el plugin, lanzar RCommander tecleando library(Rcmdr) y, una vez abierto, seleccionar la opción del menú Herramientas → Cargar plugin(s) de Rcmdr…, marcar el plugin de la lista que nos ofrece y pulsar aceptar (figura 2). El programa nos dirá que necesita reiniciar para cargar el plugin. Aceptamos y ya estaremos en condiciones de cargar la base de datos y comenzar el análisis.
Figura 2. Carga del plugin RcmdrPflgin.survival en RCommander. Mostrar/ocultar
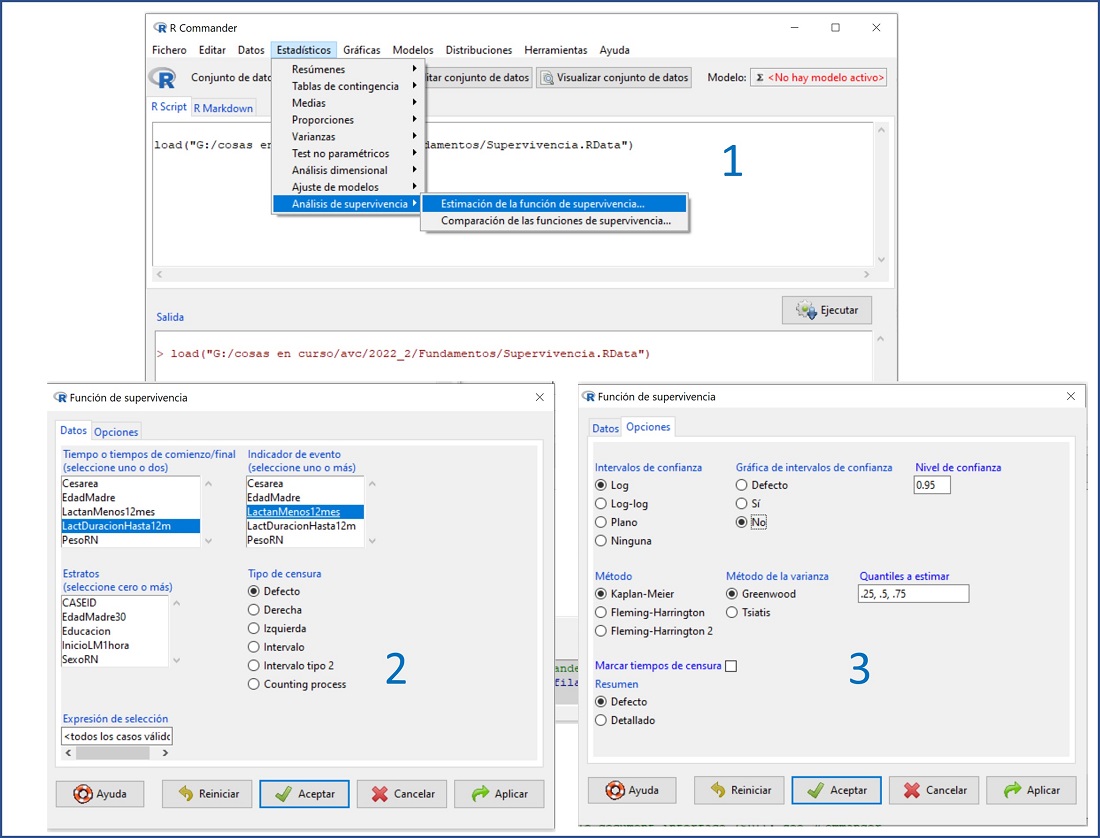
En primer lugar, representaremos la curva global de supervivencia de la duración de lactancia materna. Seleccionamos la opción del menú Estadísticos → Análisis de supervivencia → Estimación de la función de supervivencia… (figura 3). En la ventana emergente seleccionaremos LactDuraciónHasta12m como “tiempo de comienzo” y LactanMenos12mes como “indicador de evento”. Si pulsamos Aceptar en este momento, el programa nos muestra la curva de supervivencia o de Kaplan-Meyer con sus intervalos de confianza y las marcas de los datos censurados.
Figura 3. Elaboración de la curva de supervivencia global. Mostrar/ocultar
Para simplificar el gráfico, antes de pulsar en Aceptar, podemos hacer clic en la pestaña Opciones, seleccionar No en la opción “Gráfica de intervalos de confianza” y desmarcar la selección de la casilla “Marcar tiempos de censura”. Si pulsamos Aceptar, el programa generará el gráfico, tal como lo vemos en la figura 4.
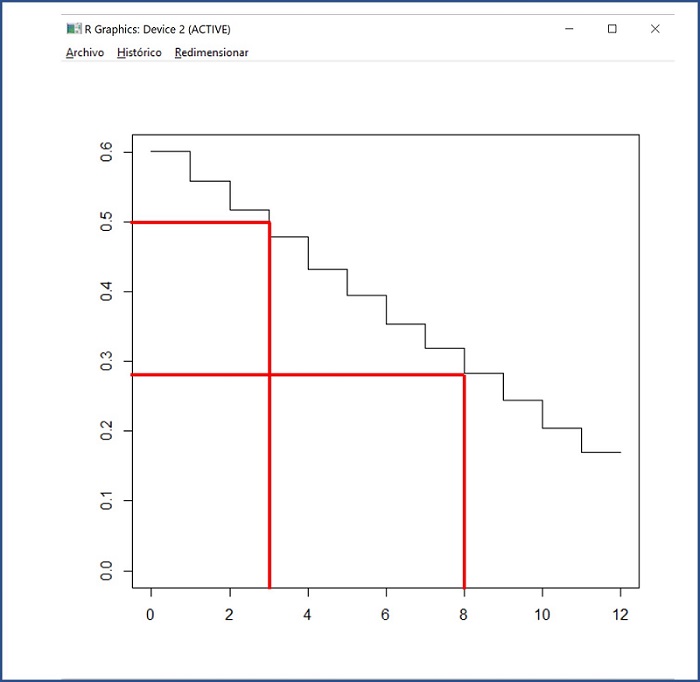
Figura 4. Curva de supervivencia global de duración de la lactancia materna. Mostrar/ocultar
En el gráfico se representa el tiempo en meses (eje x) frente a la probabilidad de supervivencia (persiste la lactancia materna) en el eje de ordenadas. Podemos de esta manera calcular la probabilidad de que aún persista la lactancia materna en el momento temporal que nos interese. Por ejemplo, a los 3 meses alrededor del 50% de los niños siguen recibiendo lactancia materna. Este porcentaje cae a alrededor del 28% a los 8 meses del seguimiento (las líneas rojas han sido añadidas para ilustrar el ejemplo, no las proporciona el programa R).
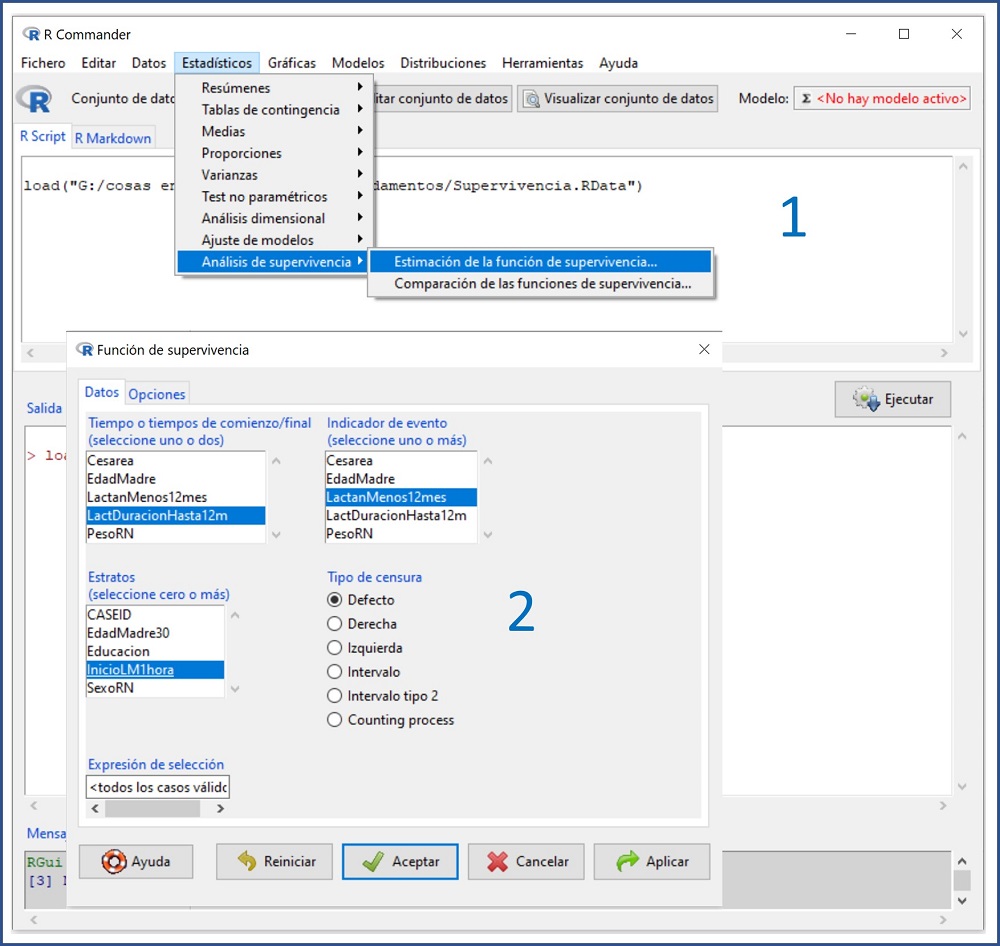
Ahora supongamos que estamos interesados en saber si la precocidad del inicio de la lactancia materna influye en el tiempo que esta se mantiene después del nacimiento. Para comparar las dos curvas según se inicie la lactancia antes o después de la primera hora de vida, seleccionamos la opción del menú Estadísticos → Análisis de supervivencia → Estimación de la función de supervivencia… (figura 5). En la ventana emergente marcaremos, en la parte superior, las mismas variables que en el ejemplo anterior. Para indicarle al programa que queremos las dos curvas según el inicio de la lactancia, seleccionaremos la variable InicioLM1hora de la ventana de “Estados”. Pulsamos Aceptar y obtenemos el gráfico de la figura 6.
Figura 5. Elaboración de las curvas de supervivencia de la duración de la lactancia materna según el inicio antes o después de la primera hora de vida. Mostrar/ocultar
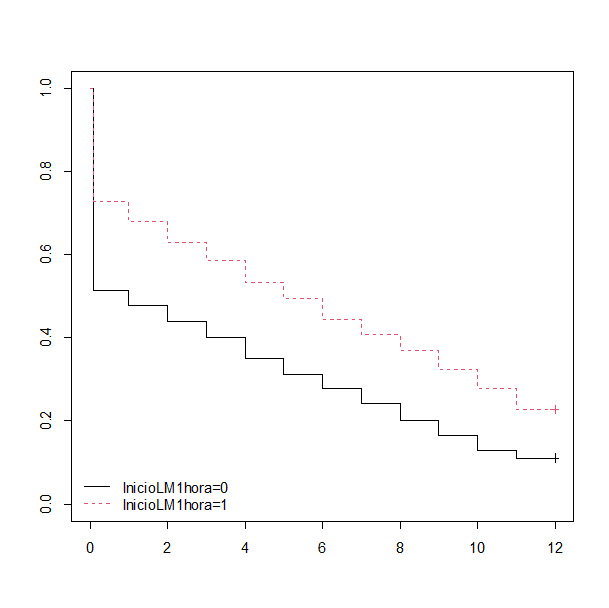
Figura 6. Curvas de supervivencia de duración de la lactancia materna según el inicio antes o después de la primera hora de vida. Mostrar/ocultar
Vemos en esta gráfica las dos curvas de supervivencia en función de la variable elegida, inicio en la primera hora. A simple vista, parece que el inicio de la lactancia en la primera hora (la variable se codifica como 1) se sigue de una mayor probabilidad de “supervivencia” de la lactancia materna, aunque prácticamente todas las madres de los dos grupos han suspendido la lactancia a los 40 meses del parto. Si queremos saber si la probabilidad de que la diferencia aparente que observamos entre las dos curvas sea debida al azar, deberemos recurrir a una prueba de contraste, como veremos a continuación.
La prueba estadística de contraste más utilizada para comparar curvas de supervivencia es la prueba de log-rank.
La ventaja de esta prueba es que tiene en cuenta las diferencias de supervivencia entre los grupos en todos los periodos de tiempo mientras dura el seguimiento. Su hipótesis nula asume que las dos curvas son semejantes y las diferencias observadas son debidas al azar. En caso de que el valor de p obtenido sea menor de 0,05, la diferencia se considerará estadísticamente significativa.
Aunque lo más habitual sea comparar dos curvas, la prueba de log-rank permite comparar también un número mayor de dos. El problema en estos casos es que un resultado significativo indica que existe heterogeneidad entre las curvas (al igual que ocurre con el análisis de la varianza), pero no nos dice qué pares de curvas son diferentes entre sí.
Continuando con el ejemplo anterior, hagamos la prueba de log-rank para determinar si las curvas de duración de la lactancia según su inicio precoz son semejantes o si existe diferencia significativa.
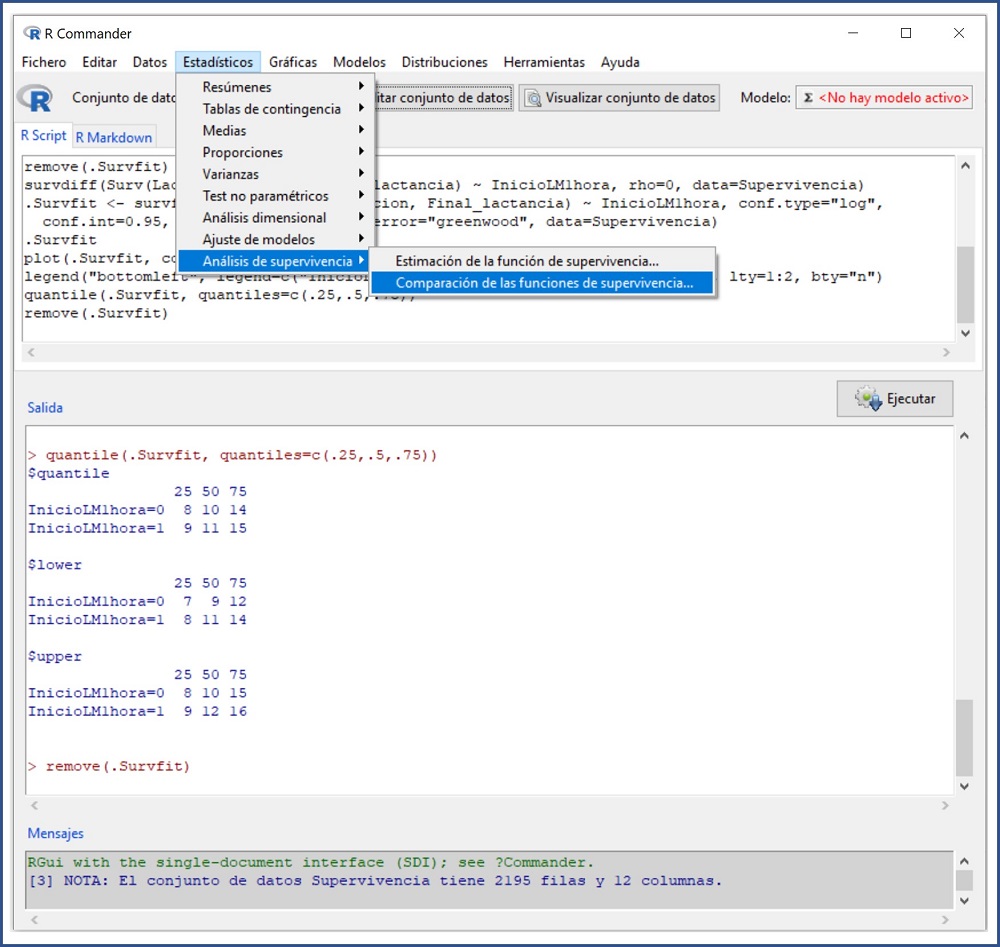
Seleccionamos en RCommander la opción del menú Estadísticos → Análisis de supervivencia → Comparación de las funciones de supervivencia… (figura 7). En la ventana emergente marcamos las mismas opciones que las que usamos para representar gráficamente las dos curvas. Pulsamos en Aceptar y el programa nos proporciona la salida de resultados que podemos ver en la figura 8.
Figura 7. Elaboración de la prueba de log-rank. Mostrar/ocultar
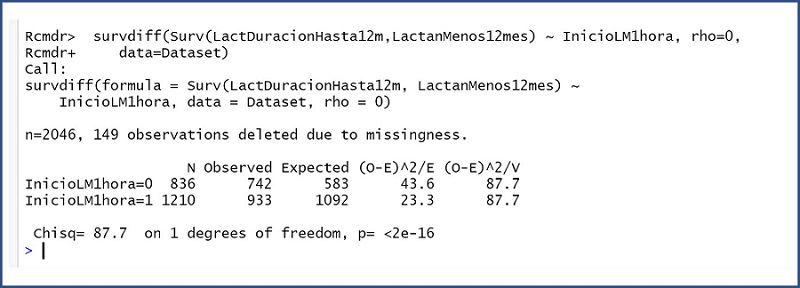
Figura 8. Resultado de la prueba de log-rank. Mostrar/ocultar
Esta prueba, similar a la de Mantel-Haenszel, proporciona un estadístico que sigue una distribución de ji-cuadrado con un número de grados de libertad igual al número de grupos menos 1. Podemos ver que el valor de p es de prácticamente cero (p= <2e-16), con lo que rechazamos la hipótesis nula de igualdad y concluimos que sí existe una diferencia estadísticamente significativa entre la probabilidad de interrumpir la lactancia materna a lo largo del tiempo según su momento de inicio (antes o después de la primera hora de vida).
Molina Arias M, Ortega Páez E, Ochoa Sangrador C. Estudios de supervivencia. Método de Kaplan-Meier. Evid Pediatr. 2022;18:20.


 Artículo completo
Artículo completo
 PDF
PDF