Buscando, por favor espere.
 Imprimir
Imprimir
 Añadir a biblioteca
Añadir a biblioteca
 Comentar este artículo
Comentar este artículo
Molina Arias M. Inteligencia artificial en Pediatría: de la ciencia ficción a la realidad clínica. Evid Pediatr. 2025;21:14.
En los últimos años hemos sido testigos de cómo la inteligencia artificial (IA) ha experimentado un crecimiento exponencial en diversos ámbitos de la sociedad, y la medicina no ha sido una excepción. Su impacto en la atención sanitaria ha sido significativo, con aplicaciones que abarcan desde el diagnóstico por imagen hasta la monitorización remota de pacientes y la personalización de tratamientos.
En el caso específico de la Pediatría, la IA ofrece un enorme potencial para mejorar la precisión diagnóstica, optimizar los tratamientos y reducir la carga de trabajo de los profesionales sanitarios, permitiéndonos dedicar más tiempo a la atención directa de los niños y sus familias, y posibilitando el desarrollo de una medicina cada vez más personalizada.
Para el pediatra, la IA presenta unos desafíos únicos en comparación con la medicina del adulto. El diagnóstico de enfermedades en niños suele ser más complejo debido a su incapacidad para comunicar síntomas con precisión, la variabilidad en la presentación clínica según la edad y el crecimiento, y la necesidad de enfoques diagnósticos y terapéuticos adaptados a cada etapa del desarrollo. Además, muchas enfermedades pediátricas son raras, lo que dificulta la acumulación de datos suficientes para mejorar la precisión diagnóstica y los enfoques terapéuticos.
En este contexto, la IA se ha convertido en una herramienta clave para abordar estas limitaciones, proporcionando modelos que aprenden de grandes volúmenes de datos y que pueden ayudar a identificar patrones clínicos de manera más eficiente y precisa que los métodos tradicionales.
En este artículo revisaremos brevemente la evolución de la IA a lo largo de las últimas décadas, se definirán sus tipos principales y describiremos sus aplicaciones actuales en la práctica pediátrica. Finalmente, se discutirán los principales desafíos y limitaciones de la IA en Pediatría, incluyendo aspectos éticos, sesgos en los datos y la necesidad de garantizar la seguridad y eficacia de estos sistemas en entornos clínicos reales.
Podemos definir la IA como la simulación de la inteligencia humana en máquinas programadas para realizar tareas que normalmente son realizadas por seres humanos, aprendiendo de datos y resolviendo problemas. Esto implica la participación de las máquinas en procesos que suponen una capacidad para imitar procesos cognitivos humanos, como el aprendizaje, el razonamiento y la toma de decisiones1.
Es importante comprender que esto supone un cambio de paradigma en la manera en que nos relacionamos con los ordenadores. Con el planteamiento clásico, damos al ordenador una serie de instrucciones (un programa informático) que debe seguir —habitualmente de forma secuencial— para realizar las transformaciones necesarias de los datos que nos proporcionen el resultado de esta operación, que será la solución al problema planteado. Para esto, debemos saber previamente las reglas que gobiernan la relación entre los datos, lo que posibilita que demos a la máquina las instrucciones necesarias para la tarea.
Sin embargo, con el nuevo paradigma lo que se proporciona al ordenador son los datos iniciales y la respuesta final, quedando a cargo de la máquina el “aprender” de estos datos para averiguar cuáles son las reglas que gobiernan la relación entre ellos, que suelen ser desconocidas con antelación por parte del investigador.
Este proceso permite a los sistemas aprender automáticamente a partir de datos sin necesidad de ser programados explícitamente para cada tarea, identificando patrones subyacentes y permitiendo realizar predicciones posteriores con datos nuevos. Es lo que se conoce con el término de aprendizaje automático (machine learning)1,2.
Aunque ya en la antigua Grecia se imaginaron mecanismos autónomos y autómatas capaces de realizar tareas específicas, la IA, tal como la entendemos en la actualidad, tiene sus raíces en la informática y las matemáticas que se remontan al siglo XIX. No obstante, su desarrollo moderno comenzó en el siglo XX con la llegada de los primeros ordenadores programables3.
Alan Turing, en la década de los años 30 del siglo pasado, fue quizás el primero en aventurar que las máquinas podrían ser capaces de razonar siguiendo una lógica similar a la del cerebro humano, aunque no es hasta la década de los 40 cuando empieza a formularse la teoría de los primeros modelos de redes neuronales artificiales4.
Suele considerarse la Conferencia de Darmouth, en 1956, como el punto de partida de la IA como disciplina científica. Es en este momento cuando se acuña el término de “inteligencia artificial”, atribuido a McCarthy.
Aunque en los años 60 comienzan a aparecer los sistemas expertos, como MYCIN, la evolución de la IA se ve limitada por la falta de capacidad computacional y el alto coste de los sistemas.
El interés por la IA resurge en las décadas de los 80-90 pero, sobre todo, durante los primeros años del siglo XXI, de la mano de la mejora de la capacidad de almacenamiento y procesamiento de cantidades cada vez mayores de datos (big data) y del desarrollo de algoritmos avanzados de aprendizaje automático y de las redes neuronales artificiales4.
Progresivamente, se van desarrollando las redes neuronales recurrentes (2007) y las convolucionales (2012), hasta llegar al desarrollo de las nuevas redes transformadoras (transformers) en 2015-2017, produciéndose finalmente la explosión de uso y popularidad con el lanzamiento de ChatGPT en noviembre de 20225,6.
Como ya dijimos anteriormente, el aprendizaje automático (machine learning) es una rama de la IA que permite a los algoritmos aprender patrones a partir de datos y hacer predicciones sin estar programados explícitamente para cada tarea.
Aunque puede hablarse de diversos tipos de aprendizaje automático, en este artículo vamos a centrarnos en dos de ellos: el supervisado y el no supervisado7.
El aprendizaje supervisado consiste en entrenar un algoritmo utilizando un conjunto de datos etiquetados. Es decir, se le proporcionan ejemplos en los que la respuesta correcta ya es conocida, permitiéndole aprender una relación entre las características de entrada y la salida deseada. El objetivo es conseguir un modelo capaz de generalizar y hacer predicciones sobre nuevos datos.
Por ejemplo, podemos proporcionar una serie de registros con características clínicas y el diagnóstico de cada paciente para que el algoritmo aprenda a diferenciar entre los diferentes diagnósticos según sus características. Una vez entrenado, el modelo será capaz de diagnosticar pacientes nuevos (cuyo diagnóstico no es conocido) proporcionándole las características clínicas.
Hablaremos de algoritmos de aprendizaje supervisado para regresión cuando la variable a predecir sea cuantitativa. Cuando el objetivo sea predecir una categoría de una variable cualitativa, hablaremos de algoritmos de clasificación.
A diferencia del aprendizaje supervisado, en el aprendizaje no supervisado no se proporcionan etiquetas ni respuestas correctas. El modelo debe analizar los datos y descubrir patrones ocultos sin intervención del investigador, por lo que este enfoque resulta útil cuando no se conoce la estructura de los datos y se busca encontrar grupos, tendencias o correlaciones desconocidas.
Aunque existen diversos algoritmos dentro de esta categoría, pueden clasificarse como métodos de agrupamiento (clustering), en los que el modelo organiza los datos en grupos según similitudes, y técnicas de reducción de la dimensionalidad, que buscan simplificar los datos y buscar las variables más relevantes.
El aprendizaje profundo (deep learning) es una rama del aprendizaje automático que utiliza redes neuronales artificiales con múltiples capas para procesar y aprender de grandes volúmenes de datos. El nombre hace referencia a las capas profundas de la red neuronal2.
Estas redes neuronales realizan tareas de aprendizaje supervisado y no supervisado, como el resto de los algoritmos de aprendizaje automático, aunque es frecuente observar otros tipos, como el aprendizaje semisupervisado, autosupervisado o el aprendizaje por refuerzo, entre otros.
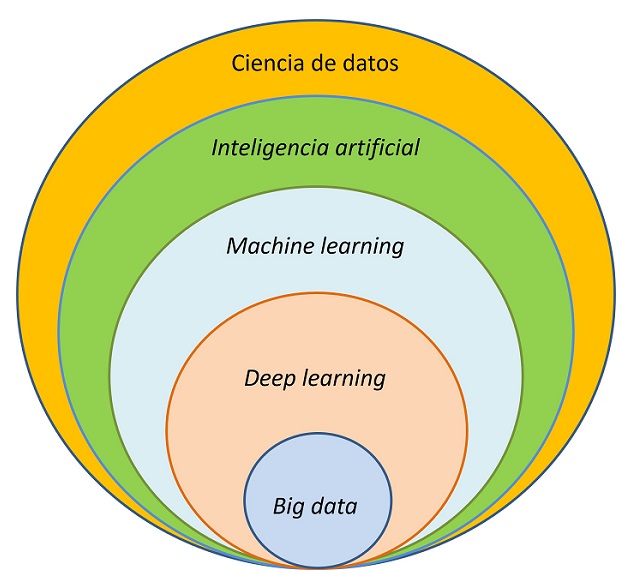
El esquema general de estas tecnologías puede verse ilustrado en la figura 1. Todos estos métodos de IA se englobarían dentro de la ciencia de datos. Hablaríamos de aprendizaje automático al referirnos a los algoritmos que aprenden de los datos para distinguir patrones y hacer predicciones. Cuando estos algoritmos sean redes neuronales artificiales de múltiples capas, entraremos en el campo del aprendizaje profundo, y cuando empleen grandes volúmenes de datos, nos referiremos a ellos como técnicas de big data.
Figura 1. Relación entre ciencia de datos, inteligencia artificial y aprendizaje automático. Mostrar/ocultar
La IA ha transformado profundamente la investigación médica y la práctica clínica en los últimos años. Su capacidad para analizar grandes volúmenes de datos, identificar patrones y generar predicciones ha acelerado el desarrollo de nuevas estrategias diagnósticas, terapéuticas y preventivas8.
En el campo de la investigación, en la actualidad la IA juega un papel importante en el descubrimiento y desarrollo de nuevos fármacos, como muestra el ejemplo de AlphaFold9, que realiza la predicción de estructuras de proteínas, y permite el desarrollo más rápido de tratamientos personalizados10.
Otra aplicación es la optimización de ensayos clínicos, en los que los algoritmos analizan datos de pacientes para mejorar la selección de candidatos, reduciendo sesgos y aumentando la eficiencia de los estudios.
Los modelos de aprendizaje automático pueden ayudar a predecir respuestas a tratamientos, minimizando efectos adversos y personalizando terapias, incluso mediante la realización de ensayos virtuales o con gemelos digitales, los llamados ensayo in silico11,12.
Además, el número de aplicaciones en la práctica médica en general y en Pediatría, en particular, es numeroso, abarcando diferentes categorías de la atención13,14:
A pesar de sus avances y la creciente aplicación de la IA en medicina, su implementación se enfrenta una serie de desafíos que debemos tener en cuenta.
Uno de los principales es la representatividad de los datos utilizados para entrenar los algoritmos. La calidad y diversidad de los datos de entrenamiento influyen directamente en la precisión y generalización de los modelos. Si el entrenamiento se hace con datos no representativos, los modelos reflejarán este sesgo y podrán perpetuar diferencias por causas de etnia, género o nivel socioeconómico, siendo menos eficaces cuando se utilicen en estas poblaciones desfavorecidas25,26.
Otro aspecto importante, especialmente en Pediatría, implica la gestión de datos clínicos sensibles, que incluyen información personal y de salud. Es fundamental cumplir estrictamente la normativa de protección de datos, llevando a cabo técnicas de anonimización que impidan la reidentificación e implementando medidas avanzadas de cifrado y gestión segura de los datos.
Por último, la utilización de herramientas de IA en medicina plantea una cuestión crítica: ¿quién es responsable cuando un algoritmo se equivoca? En la práctica médica tradicional, la responsabilidad recae en el profesional de la salud. Sin embargo, cuando una IA interviene en la toma de decisiones, es necesario determinar si la responsabilidad recae en el médico, el desarrollador del algoritmo o la institución que lo implementó.
Quizás la solución más lógica sea crear marcos de responsabilidad compartida, donde médicos y desarrolladores sean responsables conjuntamente de validar y supervisar los modelos de IA. Es necesario asegurar la transparencia en la validación y certificación de modelos, garantizando que los algoritmos sean revisados y aprobados antes de su uso en la práctica clínica.
Sin apenas darnos cuenta, la IA está dejando de ser una herramienta experimental para convertirse en un pilar esencial de la investigación y la práctica médica. Sin embargo, su integración debe realizarse con una validación rigurosa para garantizar su seguridad, transparencia y equidad en su aplicación clínica. El futuro de la IA en la medicina pasa por mejorar su interpretabilidad, evitar sesgos y consolidar su uso como un apoyo clave para la toma de decisiones médicas.
Pero su avance también genera preocupaciones entre los profesionales de la salud. El temor a que la IA sustituya a médicos y especialistas es recurrente, especialmente con el desarrollo de modelos cada vez más autónomos en el análisis de imágenes, diagnóstico y recomendación de tratamientos. Sin embargo, la historia demuestra que las herramientas tecnológicas no eliminan profesiones, sino que las transforman.
El verdadero peligro no radica en que la IA reemplace a los médicos, sino en que aquellos que no se adapten a esta nueva realidad sean superados por colegas que sí integren la IA en su práctica diaria.
De cara al futuro, la IA promete avances revolucionarios: modelos más explicables y transparentes, sistemas de apoyo a la decisión clínica más precisos, nuevas estrategias terapéuticas basadas en el análisis de datos genómicos y el desarrollo de modelos multimodales que integren imágenes, texto y datos clínicos en tiempo real. A medida que estas tecnologías evolucionen, la clave será su integración ética y regulada, asegurando que sigan siendo herramientas al servicio del médico y del paciente, y no reemplazos de la relación humana que define el ejercicio de la medicina.
La IA no sustituirá a los pediatras, pero los pediatras que sepan aprovechar la IA estarán mejor preparados para el futuro.
Molina Arias M. Inteligencia artificial en Pediatría: de la ciencia ficción a la realidad clínica. Evid Pediatr. 2025;21:14.


 Artículo completo
Artículo completo
 PDF
PDF