Buscando, por favor espere.
 Imprimir
Imprimir
 Añadir a biblioteca
Añadir a biblioteca
 Comentar este artículo
Comentar este artículo
Ochoa Sangrador C, Molina Arias M, Ortega Páez E. Inferencia estadística: contraste de hipótesis. Evid Pediatr. 2020;16:11.
En artículos previos de esta serie hemos planteado los fundamentos de la inferencia estadística. Diferenciamos en ella dos estrategias: la estimación por intervalos y el contraste de hipótesis. En este artículo expondremos los fundamentos del contraste de hipótesis, tal y como ha sido entendido clásicamente, asumiendo la utilidad de su planteamiento categórico, aunque finalizaremos exponiendo las limitaciones y potenciales errores que entraña dicho abordaje.
El contraste de hipótesis nos permite comparar dos o más alternativas, cuantificando la probabilidad de que las diferencias entre ellas sean esperables por azar. Para el cálculo de esta probabilidad nos basaremos en las propiedades de las distribuciones de probabilidad conocidas. Si la probabilidad de encontrar por azar la diferencia observada es muy baja, podemos considerar la opción de que una de las alternativas comparadas sea superior a las demás.
Recordemos un ejemplo presentado anteriormente: en un ensayo clínico se compararon dos tratamientos, A y B, en dos grupos de 100 pacientes, para prevenir recaídas de una enfermedad. En el contraste de hipótesis se plantean dos alternativas:
Recordemos que en el grupo A recayeron un 20%, mientras que en el grupo B un 40%. En el artículo previo de estimación por intervalos calculamos para el mismo ejemplo que la diferencia de proporciones era del 20%, con un intervalo de confianza del 95% de 7,6 a 32,4. Como ese intervalo no incluye el valor nulo, que para una diferencia es “0”, parece que el tratamiento A es más eficaz que el B. Sin embargo, para resolver el contraste de hipótesis debemos cuantificar la probabilidad exacta de que la diferencia encontrada sea mayor que “0”, asumiendo la validez de las asunciones requeridas por la prueba de contraste de hipótesis elegida.
Contamos con varias pruebas con las que calcular esta probabilidad. Una de las pruebas es la aproximación a la distribución normal de la diferencia de proporciones, cuyo error estándar es:
$$\ EE\space diferencia \space proporciones \space = \sqrt {{\frac{p̂_1(1-p̂_1)}{n_1}} + {\frac{p̂_2(1-p̂_2)}{n_2}}}$$
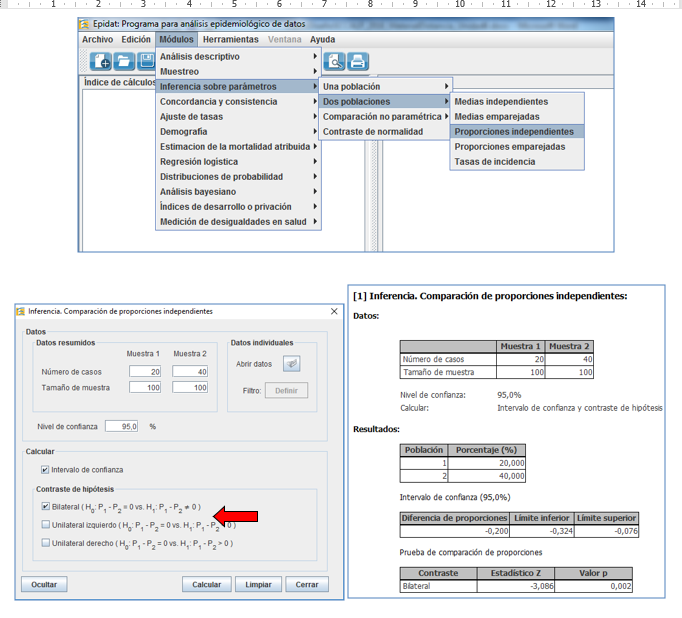
Podríamos realizar los cálculos por nosotros mismos, con el error estándar y nuestros conocimientos de la distribución normal, algo que no recomendamos. La mejor alternativa es usar alguna calculadora epidemiológica. En la figura 1 se presenta el cálculo, realizado con el programa gratuito Epidat 4.2 (disponible gratuitamente en https://www.sergas.es/Saude-publica/EPIDAT-4-2?idioma=es) para el contraste bilateral, esto es, aquel en el que la hipótesis alternativa defiende que la eficacia de A y B son distintas, o lo que es lo mismo, la diferencia entre A y B es distinta de 0 (mayor o menor). Los cálculos serían distintos si hubiéramos elegido la hipótesis alternativa unilateral, en la que solo consideramos que A sea más eficaz que B.
Figura 1. Contraste de hipótesis para una diferencia de proporciones mediante aproximación a la normal realizado con Epidat 4.2. Se presenta el menú desplegado en el que se accede a la ventana correspondiente (en calcular, debe señalarse el tipo de contraste; en este caso se ha optado por contraste bilateral). Mostrar/ocultar
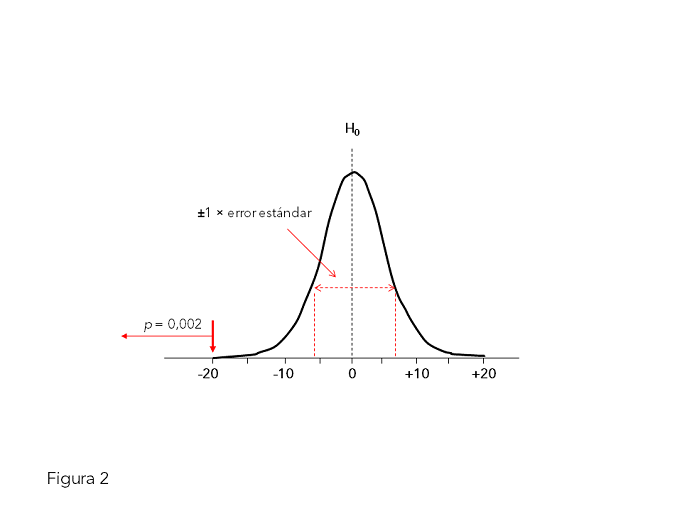
La calculadora nos informa del valor Z (distribución normal estandarizada) correspondiente a una diferencia de 0,20 (20%) en una distribución normal de media 0 y desviación estándar equivalente a nuestro error estándar (figura 2). El valor Z es 3,086 (valor más alejado que 1,96 de 0; aparece con signo negativo porque el grupo con menos recaídas lo hemos puesto primero, pero para el cálculo es irrelevante; si cambiamos el orden el valor Z sería positivo, pero a ambos les corresponde el mismo valor p), al que le corresponde una probabilidad (valor p) de 0,002 (0,2%). Como esta probabilidad es menor de 0,05 (5%), consideramos que la hipótesis nula es menos verosímil que la hipótesis alternativa; expresado con la terminología clásica, concluiremos que se rechaza la hipótesis nula (no hay diferencias) y se acepta la alternativa (el tratamiento A es mejor que el B).
Figura 2. Distribución normal de las diferencias de proporciones de media 0 (hipótesis nula [H0]) y desviación típica equivalente a su error estándar (para muestras de tamaño 100). Mostrar/ocultar
Rechazando la hipótesis nula y aceptando la alternativa asumimos un error de 0,002 (0,2%). A este error lo denominamos error tipo I, o error de falso positivo (porque asumimos que hay diferencias en la población, de la que procede nuestra muestra, cuando no las hay en la población), y a su probabilidad la llamamos alfa. Es importante advertir de que, aunque el error sea muy pequeño, siempre existe cierto riesgo de error.
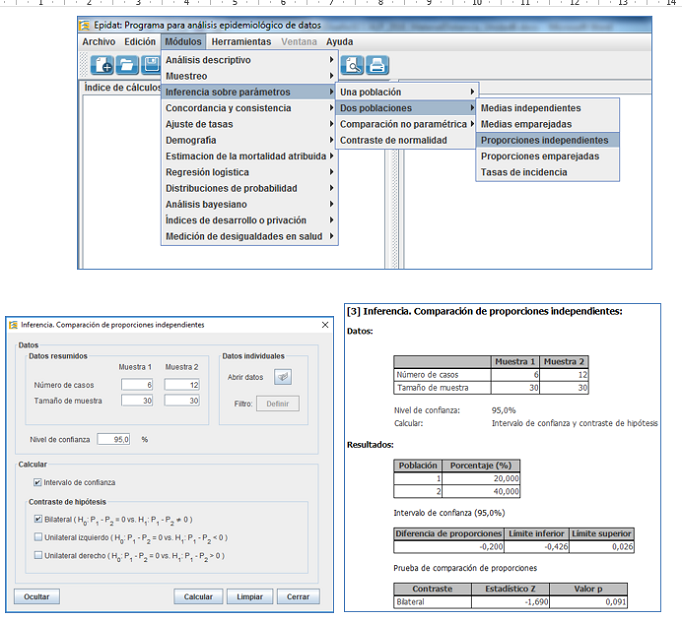
Veamos otro ejemplo. Supongamos que el estudio realizado anteriormente, en vez de contar con 100 sujetos en cada grupo, solo contara con 30 sujetos y que la proporción de recaídas fuera la misma: 20% en el grupo A (6/30) y 40% en el grupo B (12/30). En la figura 3 presentamos el nuevo cálculo.
Figura 3. Contraste de hipótesis para una diferencia de proporciones mediante aproximación a la normal Epidat 4.2. Mostrar/ocultar
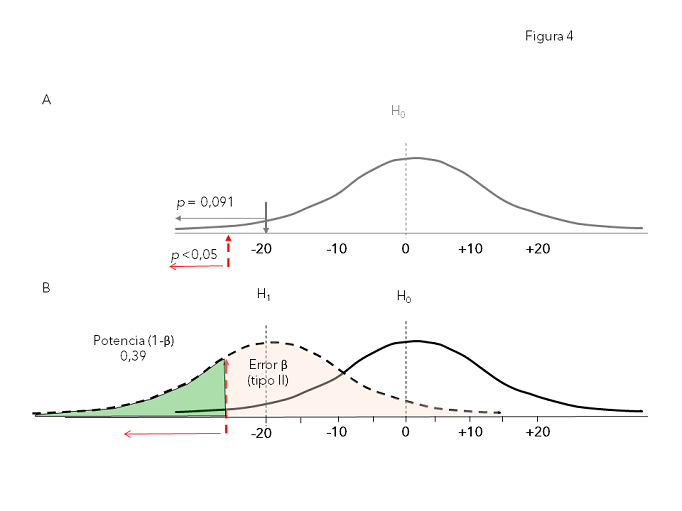
Vemos cómo, aunque la diferencia porcentual entre tratamientos es la misma, al disminuir el tamaño muestral, el error estándar aumenta y la probabilidad asociada a la diferencia encontrada cambia. La calculadora nos da un valor Z de 1,69 (menos alejado que 1,96 de 0), lo que para un contraste bilateral (figura 4A) le corresponde una probabilidad (valor p) de 0,091 (9,1%). Con este resultado no podemos considerar la hipótesis nula menos verosímil que la alternativa, porque la probabilidad de encontrar la diferencia observada no es suficientemente baja; expresándolo con la terminología clásica, no podemos rechazar la hipótesis nula ni aceptar la alternativa, ya que el error tipo I (o de falso positivo) en el que incurriríamos sería mayor de 0,05 (5%).
¿Qué ha pasado? Que el nuevo estudio ha perdido potencia, aumentando el riesgo de error tipo II (riesgo beta) o de falso negativo (probabilidad de no encontrar diferencias en la muestra cuando sí las hay en la población). El tratamiento A podría ser más eficaz que el B, pero nosotros no hemos sido capaces de observarlo con suficiente confianza. Al aumentar el error estándar la distribución normal es tan amplia que, aunque la diferencia sea grande, el valor nulo “0” es muy probable que quede dentro del intervalo de confianza (figura 4B).
Figura 4. A: distribución normal de las diferencias de proporciones de media 0 (hipótesis nula [H0]) y desviación típica equivalente a su error estándar (para muestras de tamaño 30). B: distribuciones normales de medias 0 (H0) y -20 (hipótesis alternativa [H1]). Mostrar/ocultar
Cuando las diferencias observadas no nos permiten descartar la hipótesis nula (en terminología clásica: no hay diferencias estadísticamente significativas) los resultados solo son valorables si el estudio tiene un error tipo II, cuantificado en el riesgo “beta”, menor de 0,20 (20%). Al complementario del riesgo beta lo llamamos Potencia (1-beta). Por ello, estos resultados solo son aceptables si la Potencia fuera mayor del 80%.
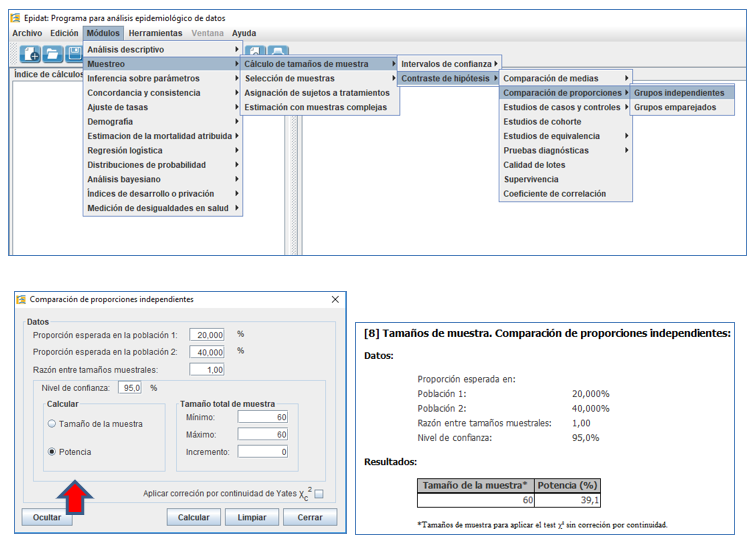
Para calcular el error tipo II (riesgo beta) o la potencia (1-beta), recomendamos usar una calculadora epidemiológica. En la figura 4B se muestra el planteamiento en el que se sustenta el cálculo de la potencia. Si realmente existieran diferencias (H1 cierta), existiría una distribución de diferencias de proporciones alternativa (H1) a la hipótesis nula (H0). En ese caso nuestro estudio podría haber encontrado cualquier valor comprendido en la distribución alternativa, pero solo los que quedan más alejados de la hipótesis nula (H0), darían una probabilidad menor de 0,05 en ella; podemos ver que ese valor es un valor más extremo que el que nosotros hemos encontrado (-0,20). En la figura 5 se muestra el cálculo para nuestro estudio.
Figura 5. Cálculo de la potencia de un contraste de hipótesis para una diferencia de proporciones con Epidat 4.2. Mostrar/ocultar
La calculadora ha estimado que, con una muestra de 30 sujetos por grupo (60 en total), la potencia para estimar una diferencia del 20% es 39,1%. Como vemos, no alcanza la potencia mínima requerida del 80%. Por ello nuestro resultado no sería valorable. Si estamos convencidos de que el tratamiento A es mejor que el B (así lo sugiere la diferencia encontrada), lo más razonable es plantear un estudio con mayor tamaño muestral.
Es importante destacar que en el cálculo de la potencia del estudio debemos introducir diferencias (proporciones esperadas en cada población) que consideremos clínicamente importantes, que no tienen por qué coincidir con las observadas en nuestro estudio. En nuestro supuesto hemos usado los datos del estudio, ya que un 20% es aceptable como diferencia clínicamente importante. Si el estudio hubiera encontrado diferencias muy pequeñas (por ejemplo 2%), para el cálculo de la potencia deberíamos haber usado diferencias que consideremos clínicamente importantes, por ejemplo, un 10, un 15 o 20%. La potencia calculada sería interpretada como que, aunque el estudio no ha encontrado diferencias, tenía potencia suficiente para haber encontrado diferencias mayores de 10, 15 o 20%. La elección de la diferencia requiere conocimientos del problema en estudio y no responde a criterios estadísticos.
Otra cuestión que hay que advertir es que si en los cálculos de la potencia queremos usar riesgos alfa o beta alternativos (por ejemplo, riesgo alfa 0,01 o riesgo beta 0,10), los umbrales de cálculo de probabilidad cambiarán. Si disminuimos el riesgo alfa aumentará el beta y viceversa; solo aumentando el tamaño muestral disminuirán los dos.
En la tabla 1 se resumen todas las situaciones posibles del contraste de hipótesis. Debemos tener en cuenta que sea cual sea la decisión de nuestro contraste, siempre existe un cierto riesgo de error, ya que la población es inaccesible. Recordemos que si el riesgo alfa es menor de 0,05 solo tendremos en cuenta la primera fila de la tabla. Cuando el riesgo alfa sea mayor, nos plantearemos el cálculo de la segunda fila, estimando el riesgo beta.
Tabla 1. Alternativas del contraste de hipótesis. Mostrar/ocultar
En el apartado anterior hemos empleado una prueba de contraste de hipótesis (aproximación a la normal de la diferencia de proporciones), pero existen muchas otras pruebas, entre las que tendremos que elegir la más apropiada para cada contraste.
En la elección del test estadístico tendremos que considerar los siguientes factores:
En la tabla 2 se presenta un esquema simplificado para la elección de la prueba de contraste más apropiada. En próximos artículos iremos desarrollando las principales pruebas de contraste de hipótesis.
Tabla 2. Esquema de elección del test de contraste de hipótesis más apropiado. Mostrar/ocultar
En los últimos años va creciendo una opinión crítica con el planteamiento categórico del contraste de hipótesis. Se critica fundamentalmente que la interpretación de los resultados de un estudio y, en consecuencia, la asunción de jerarquías de superioridad en la comparación de alternativas, se sustente exclusivamente en un umbral de significación estadística, establecido arbitrariamente en el nivel de probabilidad 0,05 (5%). Un error muy común, que observamos con frecuencia en textos y exposiciones científicas, es interpretar una p no significativa como una prueba de ausencia de efecto o asociación. También es frecuente interpretar una p significativa como una prueba de la existencia de un efecto o relación. Ni la ausencia de significación estadística (p mayor de 0,05) permite probar la hipótesis nula, ni la presencia de significación (p menor de 0,05) permite probar la hipótesis alternativa. Cualquier decisión sobre superioridad o inferioridad está sujeta a incertidumbre, que no se resuelve en función de que la p sea superior o inferior a 0,05. La interpretación de los resultados requiere tener en cuenta otros factores, como la magnitud del efecto o asociación, la adecuación de las hipótesis contrastadas, los posibles errores cometidos en el diseño o ejecución del estudio y la validez de las asunciones inherentes a la prueba estadística empleada.
Es preciso recordar que la significación estadística no informa de la dimensión o importancia de los resultados, tan solo de la probabilidad de dichos resultados en el modelo planteado por la hipótesis nula. Si el tamaño del efecto encontrado en un estudio resulta insignificante desde el punto de vista clínico, no importa su nivel de significación, ya que su aplicabilidad será cuestionable. De hecho, cualquier diferencia, por pequeña que sea, puede alcanzar significación estadística, si el tamaño muestral del estudio es suficientemente grande. En este sentido, resulta más informativa la presentación de resultados como intervalos de confianza.
Debemos ser precisos a la hora de presentar los resultados científicos, diferenciando claramente lo que es clínicamente importante de lo que es estadísticamente significativo. Para evitar confusión, parece recomendable limitar el uso del vocablo “significativo” a la indicación del nivel de significación estadístico de un contraste de hipótesis, aportando la significación exacta, sin simplificar la información en una interpretación categórica de “significativo” (menor de 0,05) o “no significativo” (mayor de 0,05). Recomendamos presentar los resultados con sus intervalos de confianza que nos informan de la magnitud y verosimilitud de los resultados. Asimismo, a la hora de interpretar un intervalo de confianza no debemos limitarnos a comprobar si en su interior se incluye o no el valor nulo (0 para una diferencia; 1 para un riesgo), sino que debemos hacer una interpretación de su valor central y de todos los valores incluidos entre los límites del intervalo.
A pesar de las limitaciones mencionadas, en ausencia de un modelo alternativo ampliamente aceptado que sustituya al contraste de hipótesis clásico, no podemos desterrarlo de nuestros análisis. Dado que estamos obligados a tomar decisiones, eligiendo entre alternativas en presencia de incertidumbre, siempre será mejor cuantificar la incertidumbre que ignorarla. El contraste de hipótesis puede seguir siendo útil si somos capaces de hacer una interpretación válida y prudente de este.
Ochoa Sangrador C, Molina Arias M, Ortega Páez E. Inferencia estadística: contraste de hipótesis. Evid Pediatr. 2020;16:11.


 Artículo completo
Artículo completo
 PDF
PDF